基于内容的图像搜索实现
/ / 点击 / 阅读耗时 24 分钟图像搜索引擎一般有三种实现方式
1、Search By Metadata,这种方式不会考虑图片本身内容(图片包含物体,以及图像像素分布等),纯粹根据图像标签来进行检索。如果某个网页中有一张赛马的图片,并且网页文本内容中包含“赛马”(或者相关词汇)的文字,当用户搜索“赛马”、“马”、“horse”等关键字时,搜索引擎就会把这张图当作检索结果返回给用户。换句话说,此时的图像搜索引擎干的事情跟普通搜索引擎差不多,匹配关键词,并将对应图片返回给用户。这种工作方式的优点是速度快,在普通搜索引擎的技术基础之上很容易改进去实现。缺点也很明显,它完全依赖于描述图片的文字(标签),如果描述图片的文字不对或者相关性不大时,搜索准确性可想而知,比如我这篇博客中如果插入一张“猫”的照片,但是整篇博客文章对“猫”只字不提,那么基于Search By Metadata的搜索引擎很难找到博客中猫的图片。有一类图片分享网站要求用户在上传图片时,人工用几个词汇描述图片中有什么(标签),便于后面基于Metadata的搜索。当然也不排除一些基于深度学习的图片分类自动打标签的方式。
2、Search By Example,这种方式考虑图片本身内容(图片包含物体,以及图片像素分布等等),用户输入图片,搜索引擎根据图片内容,返回与该图片相似的图片结果。这种方式相比Search By Metadata要复杂一些,当然如果实现恰当,准确性也更能得到保障。如果用户上传一张包含“马”的图片,那么搜索引擎会返回包含马的其他图片,或者,当用户上传一张“沙滩”的风景图片,搜索引擎会返回一堆海边沙滩的图片,这些图片包含类似的内容:沙滩、天空、大海、游客。Search By Example的方式就是我们熟知的“以图搜图”,通过一张图找出网上相似的其他图片。实现方式有很多,有基于深度学习的方式,也有传统的图像分析算法,后者也是本篇文章后面会详细介绍的部分。
3、第三种就是前两种的结合体,具体就不多说了,技术互补,到达最佳效果。
本篇文章主要介绍利用传统图像分析算法如何实现Search By Example的搜索引擎(以图搜索)。
图像指纹
人类有指纹,通过指纹对比可以判断两个人是否是同一个人,换句话说,指纹可以当作人类独一无二的标识符。图片也有类似的概念,成千上万的图片中,每张都有自己的特点,通过某种方式提取它的特征,可以作为图像对比时的关键依据。
图像指纹提取通常称为“特征提取”,在程序代码中,提取到的图像特征通常用一个多维向量或者一串64/126位二进制数字表示。特征提取的方式有很多种(后面会介绍三类),不管通过哪种方式提取图像特征,都应该保证:通过特征对比,我们可以反推原始图片的相似度。
通过图像特征评价图片相似度
假设我们已经为两张图片提取到了合适的图像特征,如何操作我们可以通过特征来反应原始图片的相似度呢?一般我们计算两个特征之前的距离,通过距离反映原始图像的相似度,如果距离越近,两张原始图片相似度更高,反之亦然。
计算距离的方式有很多,需要根据特征提取的方式来选择不同的距离计算方法,通常有以下几个距离计算方法:
(1)欧氏距离。就是欧几里德距离,这个距离应该是我们最熟悉的,在小学就接触了。我们在计算直线上两点的距离就是指欧式距离,上初中时计算平面坐标系中两点的直线距离也是指欧式距离,上高中时计算三维坐标系中两点的直线距离同样指欧式距离,四维、五维甚至更高维都是这种计算方式。每个点的坐标用多维向量表示(a1, a2,…, an)和(b1,b2,…,bn),那么两个向量之间的欧式距离为:(a1-b1)^2 + (a2-b2)^2 + … + (an -bn)^2,然后开方。
(2)汉明距离。这个距离其实普通程序员应该也比较熟悉,它指两个字符串(或者两个位数相同的二进制数)对应位置不相同的字符个数,汉明距离越大,代表两个串不相同的字符越多,两个串相似度越低,反之亦然。如果是两个二进制串计算汉明距离(1001010110)和(1001010100),非常简单,直接使用XOR(异或运算符)即可,1001010110 xor 1001010100,然后计算结果中1的个数。
(3)余弦距离。余弦距离一般程序员可能用不到,它指两个向量之间夹角的余弦值。二维平面坐标系中,向量(a1,a2)和向量(b1,b2)之间的夹角余弦值很好计算,同理,三维、四维也一样。余弦距离代表两个向量中各个分量的占比程度,比如(3,3)和(5,5)两个向量的余弦距离为0,因为每个向量中各个分量占比都为50%(3/6,3/6 和 5/10,5/10)。同理三维向量(2,3,4)和(4,6,8)之间的余弦距离也是0。两个向量的余弦距离为零,不代表它们之间的欧式距离为零。但是反过来却成立。
(4)卡方距离。卡方距离主要用于衡量两个概率分布的相似性。可以假设两个多维向量中的每个分量都代表概率(分量的和为1),那么卡方距离就是计算这两个概率分布的相似度。具体内容请网络搜索。
以图搜图实现原理
以图搜图的过程其实很简单,跟普通的检索流程差不多。关键有两个:
(1)一个是特征提取方法,这个是重点,如何合理提取图像特征是保证准确性的第一要素;
(2)二个就是如何提高特征对比的速度,成千上万张图片源,如何快速从中找出相同/相似的图片?

下面介绍三种传统图像特征提取的方式。
图像特征点
任何一张数字图片,微观上看,像素之前总是能找到一些规律的,像素分布、像素值、像素密度等等。OpenCV内置很多特征点提取算法,比如ORB、SURF以及SIFT等等。以SIFT举例,输入图片,输出该图片中具有某些特征的点(可以存在多个),从一定程度上讲,这些点可以被当作图片的标识,每个特征点用一个128维的向量表示。如果要比较两张图片的相似度,先分别提取两张图片的SIFT特征点,然后进行特征点匹配,看有多少对特征点能够匹配上,如果能匹配的点超过一定数量,那么认为这两张图片相似。这个匹配的过程可能采用前面提到的各种距离比较。下面两张图通过特征点提取、特征点匹配后得到的结果,可以判断两张图片相似:

可以看到,虽然图片拍摄角度不一样,但是包含的物体一致、场景类似,通过特征点匹配,可以找到很多匹配到的特征点。
这里的图像特征用128维向量表示,可以包含多个,如果一张图找到了100个特征点,那么每张图有128*100个float数据需要存储。
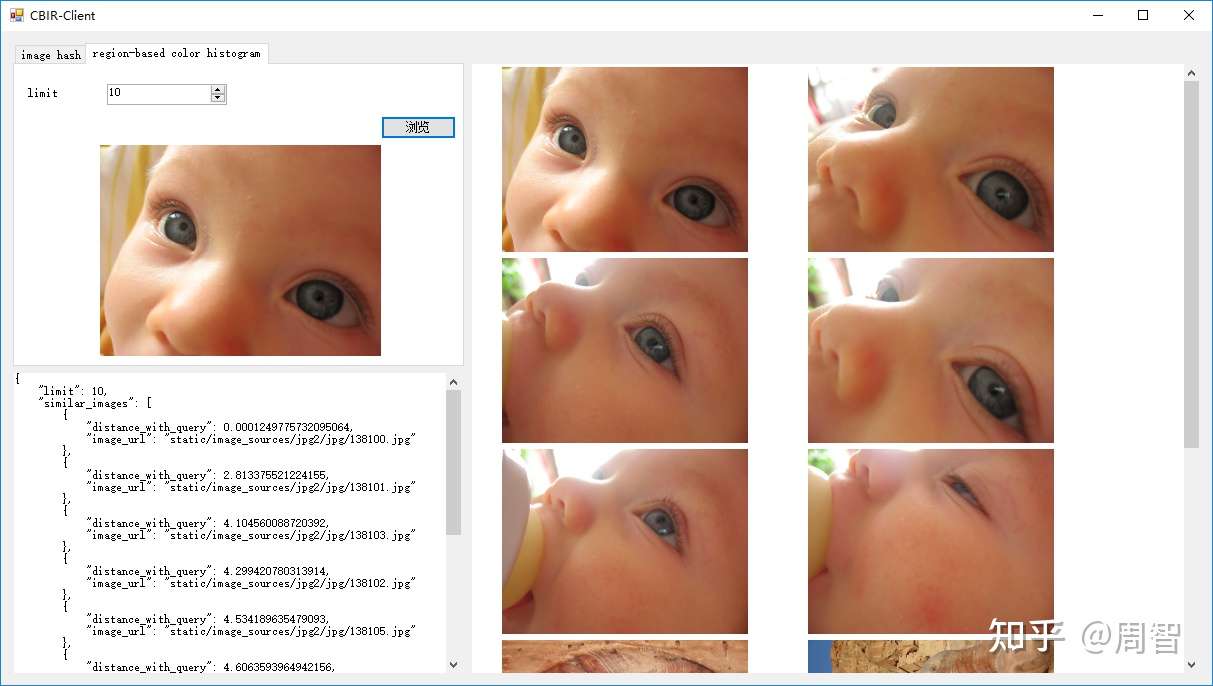
图像感知哈希
哈希算法、哈希函数我们经常听说,对于不同长度的输入,哈希算法可以产生固定长度的输出。那么我们能否直接通过计算图片文件的哈希值来判断图片是否相似/相同呢?答案是不能。这种方式计算出来的哈希值对评价原始图片相似度没有任何参考价值,因为即使是相似的图片通过这种方式计算出来的哈希值之间并不相似(可能相差十万八千里),换句话说,我们不能通过哈希值之间的距离来反推原始图片的相似度是多少。假如在一张图片上修改了一点点,最后生成的哈希值跟原来的哈希值相差很远。
因此我们需要用到图像感知哈希算法,这种方法将图片内容(更准确地讲,应该是像素)考虑进来了。通过这种方式计算得到的哈希值可以反推出原始图片之间的相似度。图像感知哈希算法常见分三类:ahash,phash,dhash。计算方式基本差不多,下面以ahash为例说明如何计算:
(1)缩放图片。直接将原始图片缩小到8*8的尺寸,不用考虑原始图片的长宽比;
(2)灰度化。将8*8的图片灰度化,这样处理后,这张图片一共包含64个像素;
(3)计算平均值。计算这64个像素值的平均值;
(4)构建哈希。将64个像素值依次与(3)中的平均值进行比较,大于平均值为1,否则为0,这样从左到右、从上到下就可以组合得到一个64位的二进制数(顺序无所谓,只要保证都按这个顺序即可)。这个二进制串就是原始图片计算出来的ahash值,格式为110010001…001001,一共64位,将其转换成16进制,得到的格式为8f373714acfcf4d0。
如何比较相似度?很简单,计算两张图ahash值的汉明距离,如果距离(不相同的位数)超过10则认为两张原始图片不相似,小于10表示相似,具体阈值需要调整。这种方式非常简单并且很好实现,而且很凑效,尤其是在一堆图片中找相同图片的时候(缩放无所谓),非常适合用缩略图查找原始图。
三种感知哈希计算方式:https://github.com/JohannesBuchner/imagehash
三种感知哈希原理说明:http://www.hackerfactor.com/blog/index.php?/archives/432-Looks-Like-It.html
http://www.hackerfactor.com/blog/index.php?/archives/529-Kind-of-Like-That.html
三种感知哈希区别和优劣势请参照网络。
这里的图像特征用64位二进制表示,每张图片的特征需要8个字节存储。
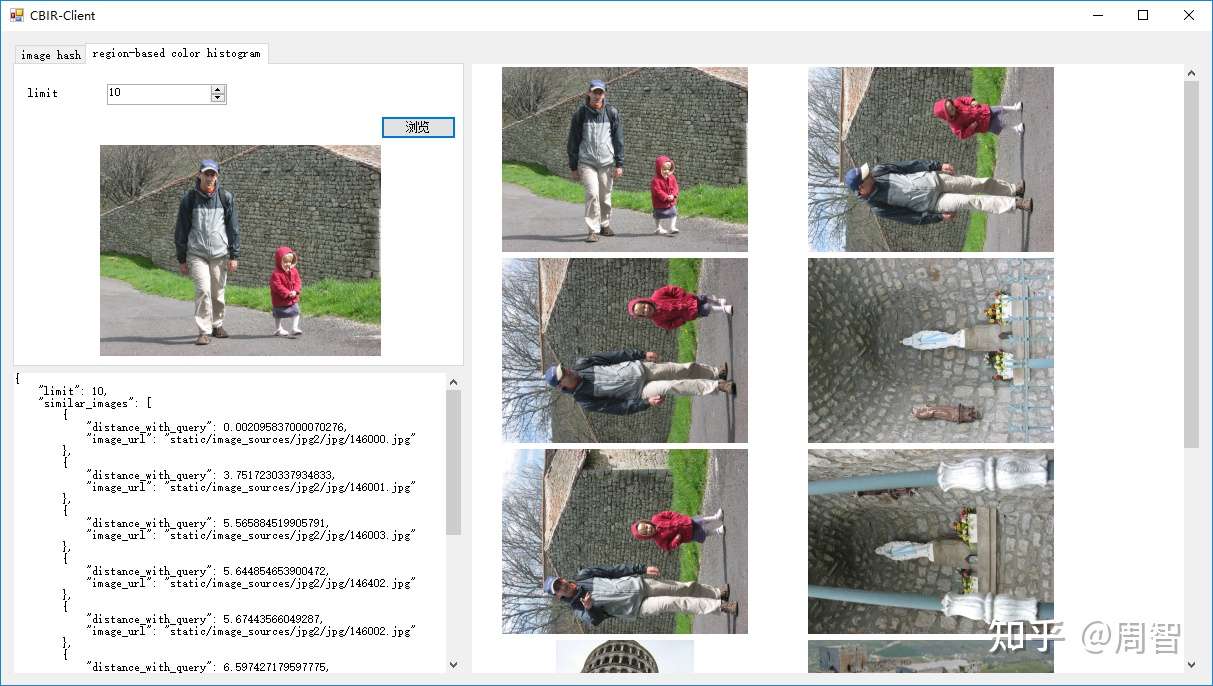
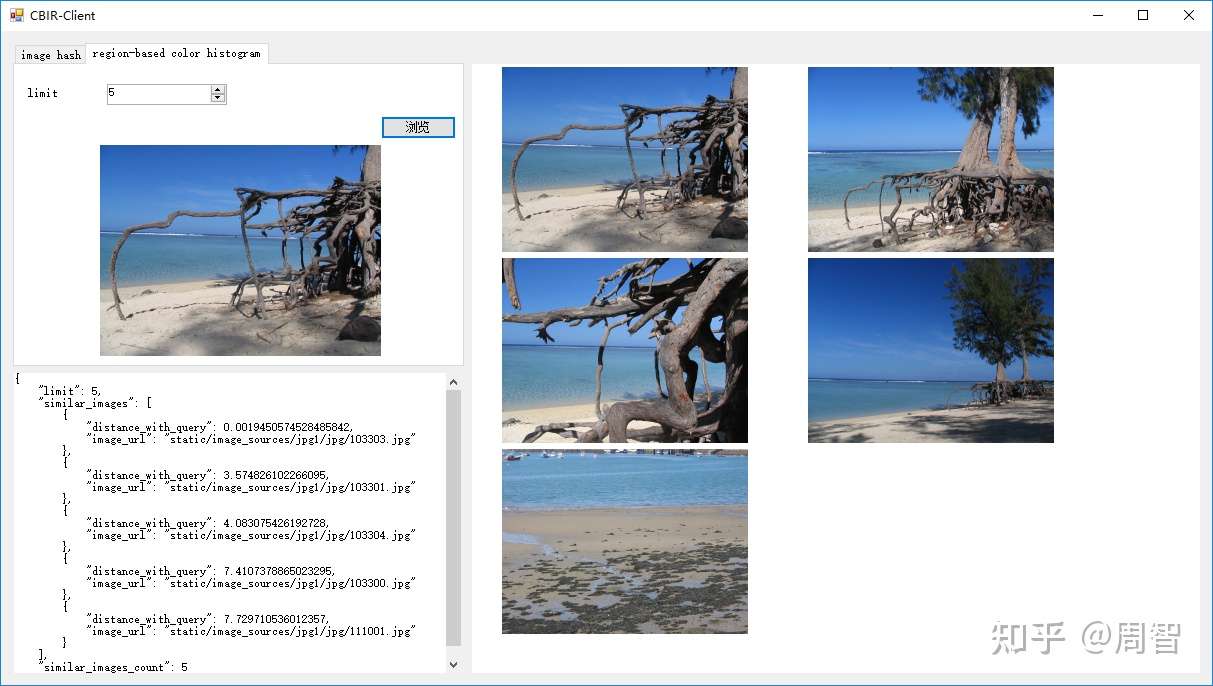
基于区域的颜色直方图
颜色直方图统计整张图片中各种像素的占比情况,严格来讲它并不考虑颜色分布在图片中的位置。而基于区域的颜色直方图在计算像素占比时,先将整张图片划分成不同的子区域,然后依次计算子区域的颜色占比情况,最后考虑子区域合并之后的结果。这种方式弥补了之前忽略颜色分布位置的缺陷,通过直方图数据评价图片的相似度更加可靠。

如上图,将原始图片划分成5个子区域,依次计算每个子区域的颜色直方图数据。图片是RGB三通道,每个通道依次分成(8,3,12)个区间,那么每个子区域颜色直方图就可以使用8312=288维向量表示。而我们又将原始图片划分成了5个子区域,那么整张图的特征就需要用 8312*5 = 1440维向量来表示了。
这里如何计算直方图特征距离呢?由于这里288维向量中每个分量代表对应区间像素出现的概率,那么距离计算就要用到前面提到过的卡方距离。通过卡方距离公式计算两个288维特征向量之间的距离,从而反推原始图片之间的相似度。
注意:使用颜色直方图的方式提取图像特征的前提是:接受“如果两张图片颜色分布差不多,则认为它们相似”这一假设,这一假设不考虑图片中具体包含内容,比如包含马、狗、人之类的目标,而只考虑颜色。事实上,经过实践,大部分时候该假设确实成立。
如何提高查询速度
给定一个图像特征,如何从一堆图像特征中快速找到与之相同、或者与之距离最近的N个、或者与之距离在M之内的所有特征呢?一个个的比较肯定不可接受,我们需要提前给这些特征创建索引,提高查找的速度。
VP-Tree是一种很好的数据结构,能够解决紧邻搜索的问题,这里是它的Python实现:https://github.com/RickardSjogren/vptree,它能够先用图像特征构建出一个二叉树,提高查询速度。具体原理请参照网络。
感知哈希+基于区域的颜色直方图demo
最后有一个demo,基于图像感知哈希(ahash、phash以及dhash)和基于区域的颜色直方图,完成了一个简单的图片搜索demo。服务端采用Python、Flask开发。