日志分析下ES/ClickHouse/Loki比较与思考
/ / 点击 / 阅读耗时 26 分钟背景与历史
ES和ClickHouse都是开源火得不行的软件,日志分析究竟该用哪个一直争论不休。这篇文章我们不比较哪个更牛,应该选哪个,而是从软件背后去分析用户需求是什么?有没有更好的方法来解这个问题。
先科普一下日志分析软件历史:
方案A:Local Storage + Pssh扫描派(代表作:跳板机上各种脚本)
在Unix设计哲学中,没有什么是不能用管道完成的。十年前没有大数据概念的时候,日志对研发而言就是随时抛弃,偶尔查问题需用一用。因此设定一定大小回滚策略+Pssh就是最不折腾的选择,所以我们在跳板机上经常能看到各种封装的shell脚本,只需要几个参数就能快速检索。方法简单粗暴,带来的局限性也挺多,例如磁盘坏数据丢失、速度慢、对线上有性能影响等。非集中式日志检索技术随着大数据兴起,使用场景逐步在萎缩。
方案B:Central Storage + Inverted Index派(代表作:ES)
说起ES不得不提到背后Lucene,Lucene实际是一个比Hadoop还早的爷爷辈软件,因为他们的作者是同一个人。Lucene是一个面向搜索引擎的倒排库,可以直接用来索引文档并提供接口来进行查询。但Lucene本身是一个Lib,离直接使用还有部分集成工作,之后Apache陆续有了Solr、Nutch等项目来帮助Lucene发展,但依然是不温不火好几年。2012年ES诞生后,通过优秀Restful API,分布式部署等机制把Lucene使用推向一个新高度。而之后 ELK(Logstash + Kibana)组合把在日志易用性上大大加速。ES 特点是通过O(1)索引,快速在海量数据上拿到结构,相比暴力扫描的方法,倒排索引速度和扫描数据量不是线性相关的。
我们来看看ES成本模型,ES 模式是通过预处理生成索引,把之后检索变成常数级操作。ES存储构成为:原始数据(正排)、倒排索引(Inverted Index)、列存储(DocValue)3种类型。数据流入时需要消耗部分机器来对数据进行编码,但在查询时只需要消耗少量的资源便可快速找到数据。之后无论多少次查询,实际成本几乎是不变的。但带来的副作用是数据膨胀,例如AWS在ES使用建议上,一般推荐预留2-3倍的空间来应对数据存储(在2 Replica情况下)。
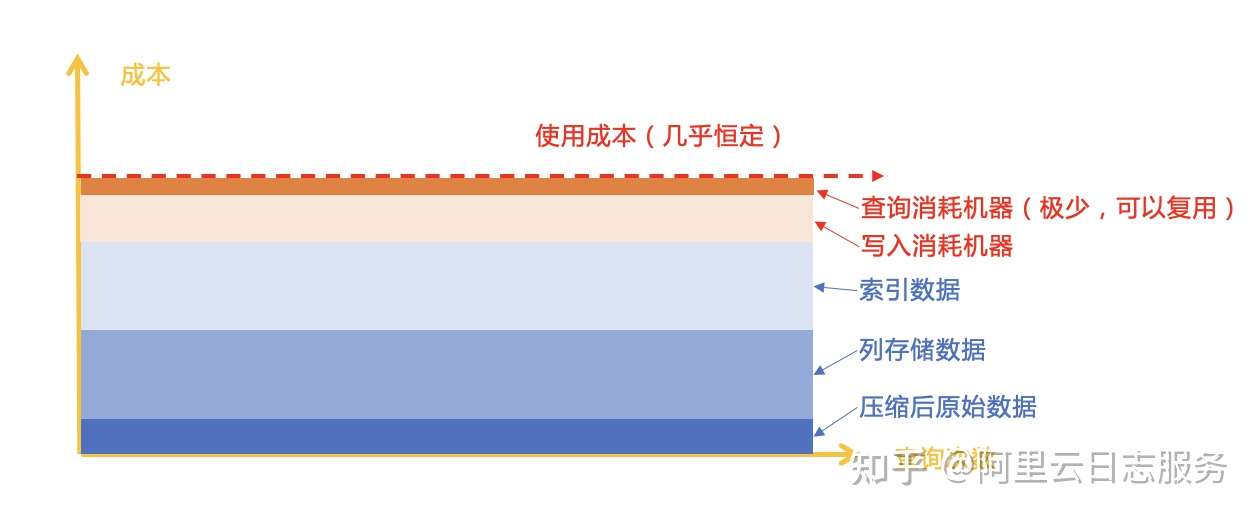
方案C:Central Storage + Column Storage + MR派(代表作:Hive)
Hadoop出现提供了HDFS分布式存储引擎,而Hive/Spark等MR引擎为了加快执行速度,天然集成了Column Storage(列存储类型),Column Storage对于类型固定的列有良好的压缩率,例如可以通过Delta、Dictionary等编码技术压缩原始数据大小,当查询时通过Histogram进行快速跳转。Column Storage对OLAP计算很友好,数据量小又能做启发式搜索。ES在五年前也推出了Column Storage类似的Doc Value技术,可以通过ES API来对列数据进行分析。
Column Storage一般会搭配一个计算引擎,基于MR的Hive、Spark提供基于磁盘的外排能力,除了执行速度慢一些之外,几乎能够胜任所有的SQL92查询分析需求。
方案D:Central Storage + Column Storage + MPP派(代表作:ClickHouse)
MR方案可以通吃从小到大的各类场景,但带来的缺点是速度不够快,并发不高,不适合实时性高的场景。之后Druid、Presto等MPP引擎诞生通过内存来代替磁盘交换,把Query执行速度大大提升。最近2年ClickHouse横空出世吸引了不少粉丝,ClickHouse秉承俄罗斯人的简单粗暴出奇迹特点,把用Hand Craft计算发挥得淋漓尽致。虽然ES也在向OLAP领域进军,ClickHouse未来也会做倒排索引,但这背后存在一个不争的事实。日志分析除了日志的TP,也会有少量的AP情况需要混合考虑。
Hive和MPP成本模型如下,数据写入一般需要前端机对数据进行转换,在读取时需要对数据进行排序过滤等,消耗一部分计算资源。
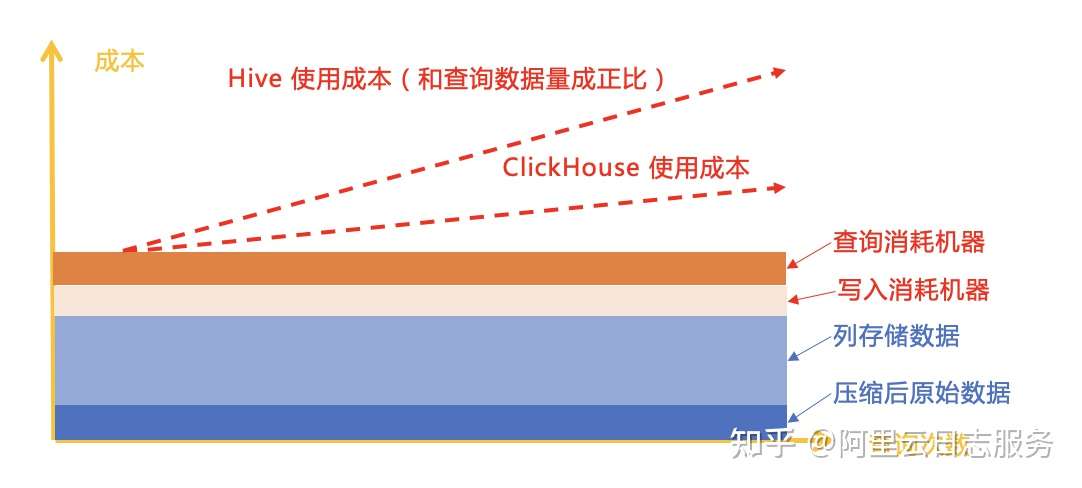
方案E:Central Storage + 扫描类(代表作:Grafana-Loki)
扫描压缩后的原始数据,看起来像是“返璞归真”的技术退化。但似乎又是一种顺应时代的做法。这个方案典型的代表是Grafana旗下Loki。Grafana因为没有存储技术的积累,因此光脚不怕穿鞋的,直接出了一个将日志直存对象存储 + 扫描方案。这个背后的理由也说的过去,云存储是未来是能够保证持续间隔竞争力的,而大部分日志是写多读少的,在一些场景下慢一些似乎也没什么差别。
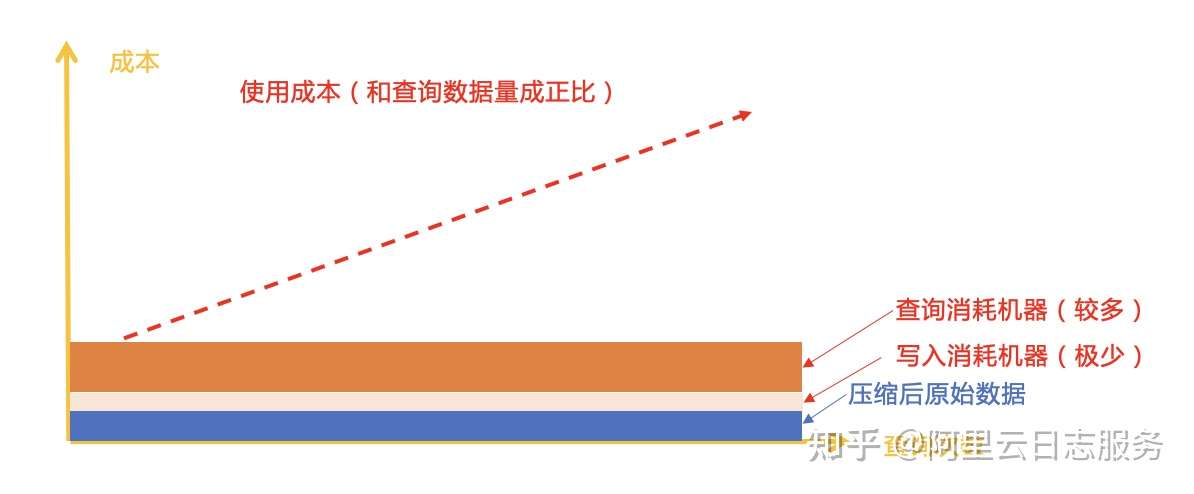
Loki方案占据存储成本极少,原始数据会以压缩方式写入,同时也可以通过列存(Parquet)来存储数据,以加快分析速度。当查询时解压缩原始数据,进行过滤,最后拿到结果。由于受限单机引擎,在查询速度、分析能力上比不过ES、Hive、ClickHouse等方案,但胜在便宜。如果数据只是偶尔查一查,要啥自行车呢。
综合对比
我们把上述方案做一个对比,如下:
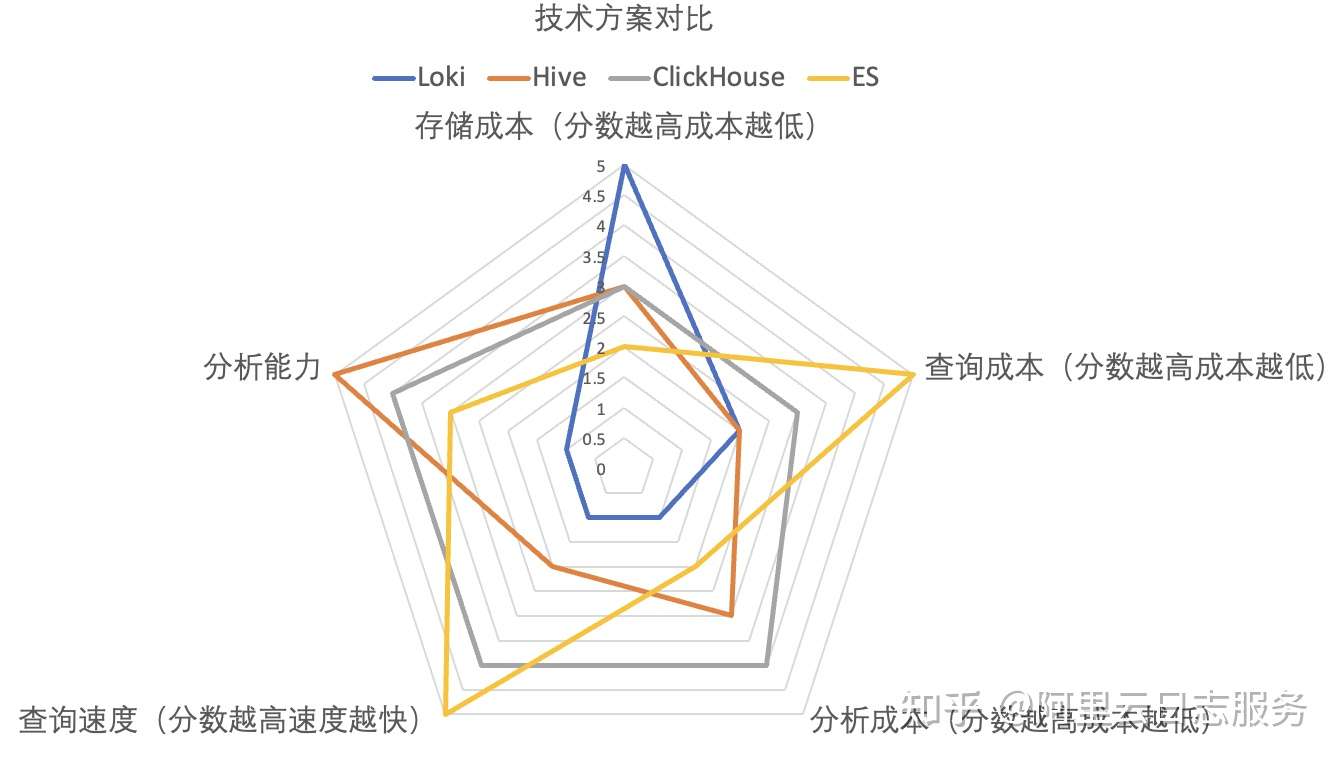
- 存储成本:Loki存储是裸数据,经过压缩后理论上空间是最小的。ES存储内容最多,因此存储成本比较高。而Hive、ClickHouse因只有列存,相对较小(对于比较随机的纯文本数据,列存理论上和字符串压缩接近)。
- 分析能力:Hive支持完整SQL92,并且没有计算量的限制,分析能力最强。ClickHouse支持的是有限SQL集,对常见的场景足够用。接下来是ES、Loki最弱。
- 查询速度:在建立索引情况下,ES是当之无愧的王者。基于MPP引擎的ClickHouse次之(对于带计算的分析,ClickHouse是最强的)。
- 分析成本:Loki最高,读取数据后大部分工作都需要外围完成。
- 查询成本:ES读取数据量最少,因此最优,接下来是ClickHouse,Hive和Loki。
从需求角度而言,是否有一种更综合架构?
为什么会有这么多的选择呢?主要是由二个因素决定的:处理需求 vs 实现成本。我们先从需求出发,看看业务需要什么?
处理需求
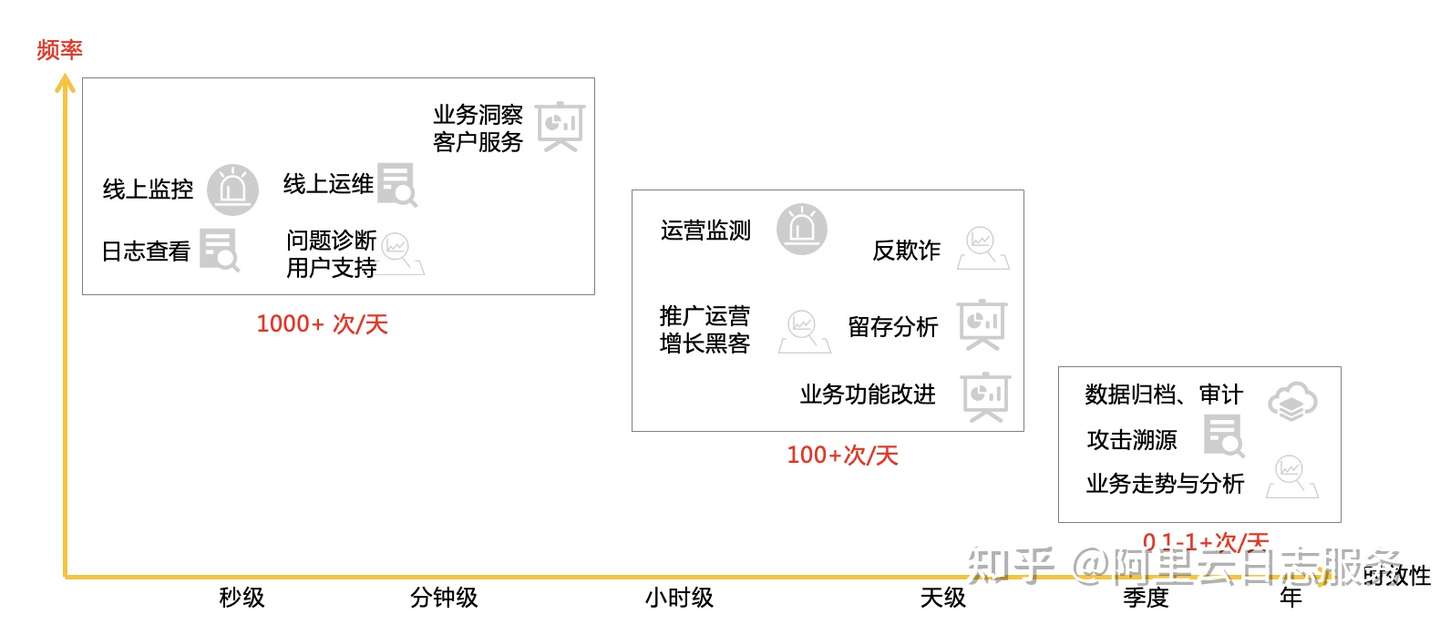
对Nginx、App访问日志而言,一般有如下典型用途:
- 第一阶段(数据产生1分钟内):程序要看到实时业务,运营客服人员需要查看轨迹定位问题。这种场景一般都在小时内, 查询频率比较高。
- 第二阶段(数据产生1-2小时左右):业务需要洞察数据,一般都是小时级或天级别。查询频率一般,往往也都是针对于聚合后的数据。
- 第三阶段(一天后):审计需要,业务需要看趋势数据。查询频率比较低,往往是点查(例如回溯一个历史问题)。
第一阶段:实时性和延时更重要
这个阶段数据实时性变得无比重要,例如用户付款投诉时,我们需要快速通过TraceId来定位后台的用户行为。我们需要根据业务访问的QPS、下单率等快速在日志中找到错误日志。需要根据业务流量情况、趋势来调度资源。
典型的访问如下:
| 访问模式 | 对实时性的要求 | 对延时的要求 | 访问频率 | 技术选型 |
|---|---|---|---|---|
| 查询所有访问记录中,负责某些条件的请求Latency>5000 and Host:http://www.example.com | <1 分钟 | 秒级 | 出问题后较高 | ES |
| 对查询结果进一步Drill Down,进行统计分析Latency>5000 and Host:http://www.example.com | select top10 userid | <1 分钟 | 秒级 | 出问题后较高 | ES、ClickHouse |
| 统计当前访问量的趋势,并对异常情况做告警select sum(1) as qps, avg(Latency) as l, p99(Latency) as p, time_windows(t, ‘second’) as t group by t desc | <5 秒 | <秒级 | 较高 | TSDB,ClickHouse |
| 查询某个用户,或某个TraceId情况TraceId:12345 | 分钟级 | <秒级 | 较高 | ES |
这个阶段大部分分析都是集中在最近5分钟时间内的数据,这些数据会被频繁访问到,并且Query条件变化范围会非常大。比较典型组合是TSDB/NoSQL/SQL + ES + ClickHouse,存储和计算成本会稍微大一些,但比起线上关键业务而言花一些钱还是值得的。
第二阶段(天级):比拼分析能力
第二个阶段业务需求会更复杂,这个阶段主要面向的是精细化需求。例如从延时、成功率等指标去度量接口稳定性,服务质量等。运营根据数据对比来发现群体特征,用来构筑质量体系等。运营会根据数据来确定投放、牵引等策略。
这个阶段访问模式包含两种:
| 访问模式 | 对延时的要求 | 访问频率 | 技术选型 |
|---|---|---|---|
| 根据某个Key查询已计算好的数据,例如用户特征等 | 越快越好,秒级 | 百万次 | 计算后存储ClickHouse、Hbase、MySQL等进行访问 |
| 根据灵活需求透视数据 | 秒级、分钟级 | 几十次/天 | ClickHouse,Hive |
第三阶段(月级):比拼成本
这个阶段数据的访问往往两极分化:趋势型分析,一般可以通过预处理技术提前降低数据量来解决。大规模数据的统计、大规模数据中查找极小部分数据。后者一般发生的概率非常低,但每次几乎都是突发需求,如果能在较短的延时内获得结果对体验是最好的。
| 访问模式 | 对处理延时的要求 | 访问频率 | 技术选型 |
|---|---|---|---|
| 对长时间、大数据进行分析 | 无 | 几次/天 | Hive |
| 查看长时间趋势性数据 | 秒级 | 十几次/天 | 预计算后存储Hbase、MySQL后访问 |
| 应对突发查询需求,例如查询某个用户长时间行为 | 分钟基-小时级 | 较低 | ES、写程序Scan |
| 应对突发导数据需求,将某些数据导出到其他位置 | 小时级 | 极低 | Hive、写程序Scan |
| 定量分析 |
实现成本
存储成本
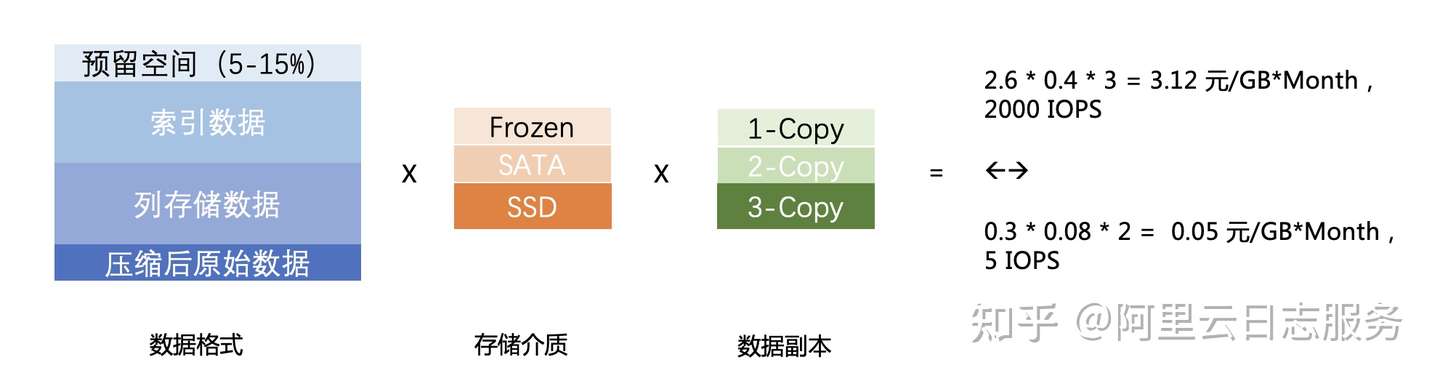
原始数据量为X,倒排索引的数据量为原始数据的a倍,列存储空间为原始数据的b倍,需要预留的空间(例如redo log、reserved space)为c倍,每GB介质成本是e,为了保证可靠性,需要的副本是d。存储成本为
,经过我们对不同存储计算,每GB成本范围在每月0.05 元/GB到3.12元/GB之间。当然这个背后查询延时与IOPS也是不同的,例如成本更高方案可以支持1000次/S IOPS,而低成本方案只能做到5次/S,在多人使用情况下可能会被打爆。
计算/处理成本
做个简单的计算,可以分解为,需要处理X GB原始数据,需要消耗的资源。在业务模式固定场景下,我们可以根据处理费用,查询费用计算出需要消耗的计算资源,例如100Core、50GB内存,最大化降低计算成本。
在有一些特殊场景下,例如突然遍历几个TB数据,计算、查询某个结果情况下,需要额外计算机器+提供额外IOPS能力。
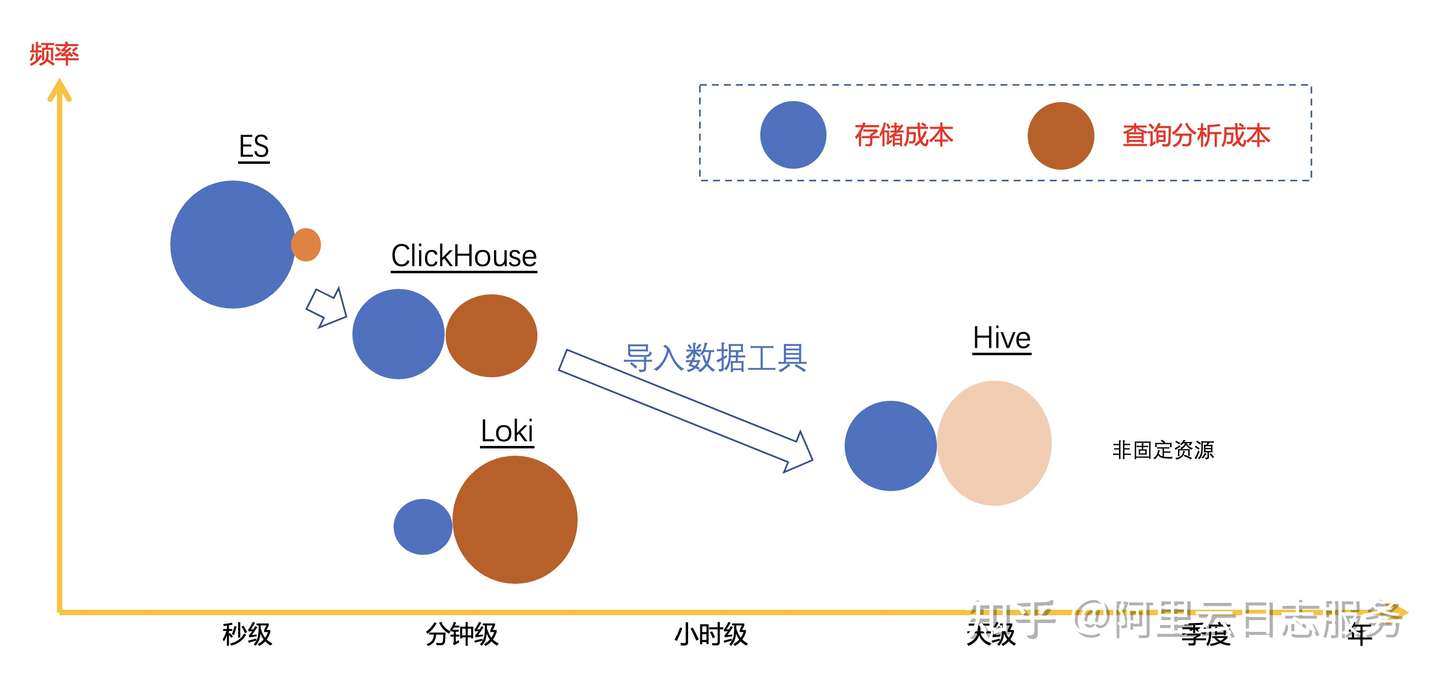
从以上定量分析我们可以得到:
不同类型的方案,本质上是IOPS、Latency、成本三个因素的平衡。
三个因素不同的比例,满足各个阶段业务需求,是否需要实时性、访问频率如何、IOPS如何,突发性怎么样。
不同方案之间,可以通过数据同步工具(例如Kafka)来迁移。
阿里云如何解决这个问题?
日志分析是一个如此通用的需求,在阿里、蚂蚁金服内部也有这样一套基础设施-SLS(日志服务),支撑数万工程师每日十几亿次的分析需求,涉及研发支撑(DevOps)、大数据运维(AIOps)、大数据安全(SecOps)、成本分析与增长(BusinessOps)等场景。
SLS解决以上问题主要思路如下:
- 一套统一数据访问接口
ES、Hbase、MySQL、ClickHouse、Hive都有自己的API,为了能够对接不同的应用场景,为了使用得在上层做大量的开发工作。当目标系统发生变化时,我们需要数据迁移工具,例如Kafka、Flink等进行数据ETL与转化。
而在SLS设计中,数据的查询分析都通过SQL进行(也能通过标准JDBC访问),这样无论是查询时序数据、Log、Trace数据都能快速拿到结果,最大程度上支持DevOps工具、上层业务创新。
更多参考:
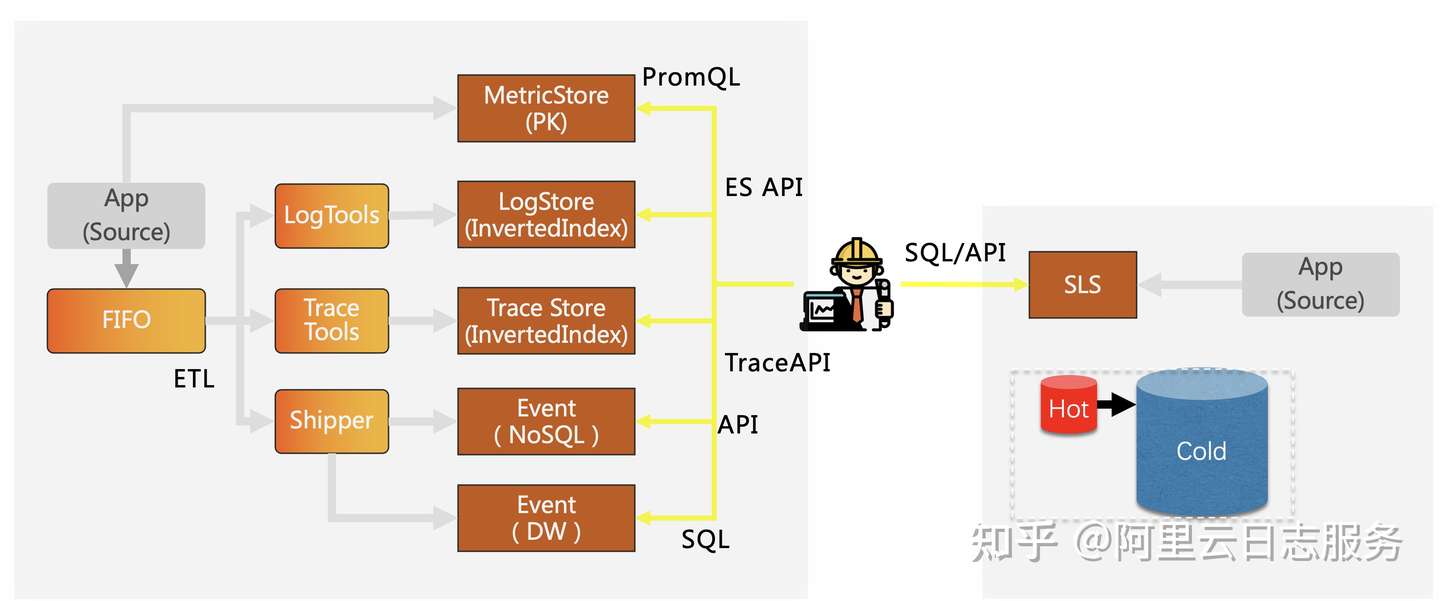
- Serverless存储+计算设计,低成本弹性能力
SLS 提供统一存储与计算能力,相对其他方案:
- 默认提供N副本(对用户透明),保证可靠性。热数据存储单价为0.35元/GB*Month,冷数据存储单价仅为1/3(即将上线),超过6个月数据,在使用不变情况下可以设置为冷存储降低成本。
- 写入按量收费,无预留收费,可以精确规划成本。
- 查询分析免费(99.9%情况下),每秒钟可以提供千级IOPS查询能力,几十IOPS分析能力(相当于能并发Hive/ClickHouse查询),无需预留资源。
- 当因业务需要突发大数据查询场景时(0.1%情况),可以申请独立计算资源加速,而无需数仓方案等待几十分钟出结果。
更多参考:
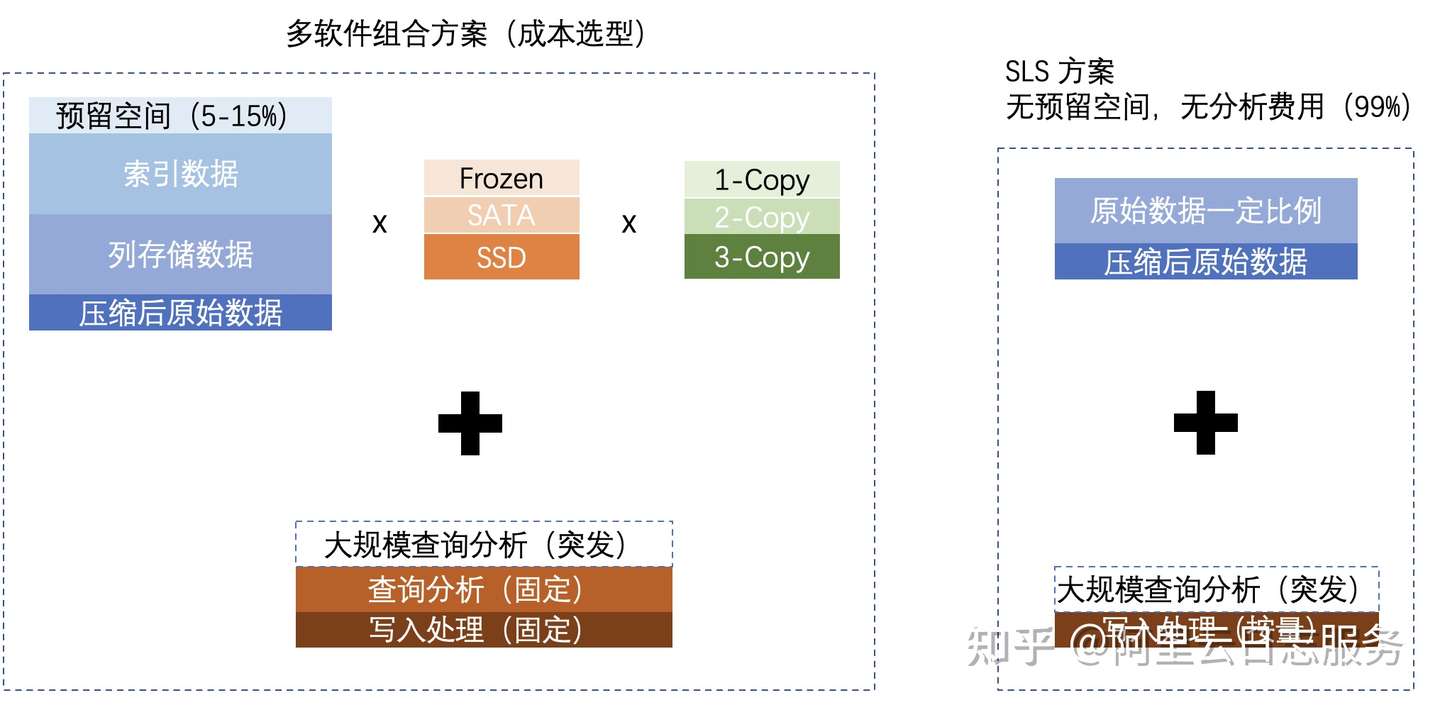
- 提供BuildIn内部数据流动,降低成本
SLS提供Schedule SQL、ETL等批处理、流处理机制,帮助应用在不同数据源之间流动。
参考: