K8S 网络之深入理解 CNI
/ / 点击 / 阅读耗时 32 分钟引子
谷歌:“我说小刀儿(docker)啊,你看我们已经在 kubelet 的代码里内嵌了 docker-shim 好久了,最近 rkt 也想让我们接进来,你看是不是咱整个规范,你也按照规范改改 docker 呀,这样以后 k8s 就海纳百川了~”
docker:“滚!”
谷歌:“……”
………………
谷歌:“我说,那个 CoreOS,还有那边那个 linux 基金会,还有那边那几个大厂,你们都过来一下。”
谷歌:“我要给我的 k8s 对接容器这块儿制定个规范,你们就说支不支持吧!”
其他大厂:“好的大哥!”
………………
新闻:“k8s 宣布于 1.20 正式弃用 docker(docker shim)!”
docker:“卧槽!爸爸我错了!”
正文

一、CNI 简介 1 - 先导小知识
K8S 已经在很早前的 1.20 版发布之前就宣布要移除内嵌在 kubelet 中的 docker shim 的代码,大概原因就是谷歌一直在 k8s 中使用一套叫做 CRI(container runtime interface)的规范,该规范旨在定义 k8s 如何更好地操作容器技术,该规范大概分为三部分:CRI Client,CRI Server,OCI Runtime。
简单来讲,就是在 kubelet 中放一个 grpc 的客户端,这个客户端要和一个 grpc 的服务端进行通信,这个 grpc 的服务端里头进行容器的“拉起”,“销毁” 等动作的调用,而真正执行 “拉起”,“销毁” 等动作的代码由 OCI Runtime 实现。

或者再简单点,对应到实现来说:CRI Client 端有个实现就是 kubelet,CRI Server 端有个实现叫 Containerd,OCI Runtime 有好多实现其中有个叫 runc。然后把他们串起来就是:kubelet 在做完了一些准入校验,CSI 的存储卷挂载等操作之后,要去拉起一个 pod 了,在拉起 pod 的时候,就先启动一个 grpc 的客户端,然后与 Containerd 中的 grpc 的服务端通信,告诉它说要拉起一个 pod 了。然后 containerd 收到后会按照一定的流程去“拉镜像”,“创建 sandbox”,“创建 netns”,“启动容器”,“创建容器网络”,“把容器加入到 sandbox” 中等。containerd 基本上只负责调用(高级运行时),真正实现这些功能的地方在 OCI 的 runc(或其他低级运行时)中,有点像是通常服务端的 controller 和 service。
不同的低级运行时因为实现逻辑以及调用逻辑可能都不太一样,就比如 runc 是利用 namespace,kata 是直接起的 qemu 虚拟机,因此 containerd 到 OCI 之间还会有一层 shim,containerd 到 runc 有 runc-shim,到 kata 有 kata-shim。
所谓的废弃 docker,其实不是真的直接干掉 docker,而是上面我们说 CRI 规范要有个 grpc 的 client 和 server 端嘛,然后 server 端通知 oci 里头去创建 ns 或者创建网络等,但是对于 docker 来讲,docker 内置了创建网络,创建存储卷等功能,在 k8s 里,这些功能比如挂载存储功能由 CSI 实现,挂载网络由 CNI 实现等,所以 docker 很多功能 k8s 并不需要,因此 kubelet 内嵌了一个 docker-shim 作为 grpc 的 client 端用来屏蔽掉 docker 的一些内置功能后再和 containerd 通信,所以其实对于 k8s 来讲,这个 docker-shim 是个冗余的负担,因此所谓的“废弃”,指的是将 docker-shim 的代码从 kubelet 中移除,在减负的同时也能通过让第三方实现 CRI 规范中的东西而接入到 k8s 里。
二、CNI 简介 2 - 正文
罗里吧嗦半天,终于说到真正的正文。
本次我们想介绍的,就是上面的 OCI 规范中有一步叫 “创建网络”。对于 k8s 来讲,网络属于最重要的功能之一,因为没有一个良好的网络,集群不同节点之间甚至同一个节点之间的 pod 就无法良好的运行起来。
K8S 在设计网络的时候,采用的准则就一点:“灵活”!那怎么才能灵活呢?答案就是“我不管,你自己做”~
没错,k8s 自己没有实现太多跟网络相关的操作,而是制定了一个规范。该规范贼简单,一共就三点:
“首先!有一个配置文件!配置文件里写上要使用的网络插件名儿,然后以及一些该插件需要的信息”。
“其次!让 CRI 调用这个插件,并把容器的运行时信息,包括容器的命名空间,容器 ID 等信息传给插件”。
“最后!你这插件自己爱干啥干啥去吧,都嚯嚯完了玩够了给我吐一个结果,结果里头能让我知道你给 pod 的 ip 是啥就行了”
没错一共就这三点,这就是大名鼎鼎的 CNI 规范!
虽然简单,但足够灵活!因为我啥也不干!
不过恰恰就是因为 k8s 自己“啥也不干”,所以大家可以自由发挥,自由实现不同的 CNI 插件,反正 pod 的相关你都给我了,我要的配置也都通过配置文件设置好了,那我作为插件的实现方,当然就可以 free style 了,反正最终目的就是能让 pod 有一个健康的网络就好了嘛~
因此就有了现在如此多的网络插件,比如 flannel,这个是利用的静态路由表配置或者 vxlan 实现的网络通信。再比如 calico,是通过 BGP 协议实现了动态路由。再比如其他还有什么 Weave,以及 OVN 之类的各种各样的网络插件。这些插件虽然实现的方法各式各样,但是最终目的只有一个,就是让集群中的各种 pod 之间能自由通信。
在 k8s 中,由于不同的 pod 可能遍布在同一个节点上,也可能在不同节点上,因此在 k8s 的网络环境中,需要解决的问题大概有如下三点:
- pod ip 地址的管理
- 同一节点上的 pod 之间互相通信
- 不同节点上的 pod 之间互相通信
基本上只要想好了方法解决这三个问题,那我们就可以自己实现一个 CNI 网络插件了。
三、在?看看 demo?
我们可以简单看几个网络插件的例子。
比如我手边集群上的网络插件使用的是 calico,我们就可以在 /etc/cni/net.d 目录下看到其对应的配置文件:

我们可以看到有个 .conflist 结尾的文件,是的,k8s 的 cni 允许同时使用多个插件,并且会把上一个插件的执行结果作为参数传递给下一个插件,以此我们可以串通多个插件,让多个插件做不同的事情,比如我可以第一个插件只负责让同一台主机上的节点通信,然后第二个插件可以负责让不同节点上的 pod 通信,总之还是那句话,配置文件有了,pod 信息也被 k8s 传过来了,爱怎么玩儿是你插件自己的事儿了~
我看还可以再简单个 flannel 的配置文件:

我手边没有用 flannel 的集群,因此就直接上 gayhub 上截图了。我们也可以看到,和 calico 的配置文件长得还比较像。其中 “name” 和 “cniVersion” 都是必须的字段,对于 .conflist 来说,”plugins” 也是必须的字段,然后还有一个 “type” 字段,也是必须的,因为 kubelet 通过这个字段来查找要使用哪个插件。
插件的默认存放地址在 /opt/cni/bin 这个目录下,该目录下都是 k8s 可以使用的网络插件,如果谁自己实现了个 cni 插件的话,给它搞成二进制的可执行文件后,往这目录下一扔就 ok 了,我们来简单看一下:

可以看到,对应的 calico 或者什么 flannel 之类的网络插件都在这个目录下了。
当然了,集群中的每个节点上在 /opt/cni/bin 和 /etc/cni/net.d 目录下应该都要有相应的配置文件以及对应的二进制可执行文件。我们可以来简单看下 gayhub 上 flannel 的 yaml 文件:
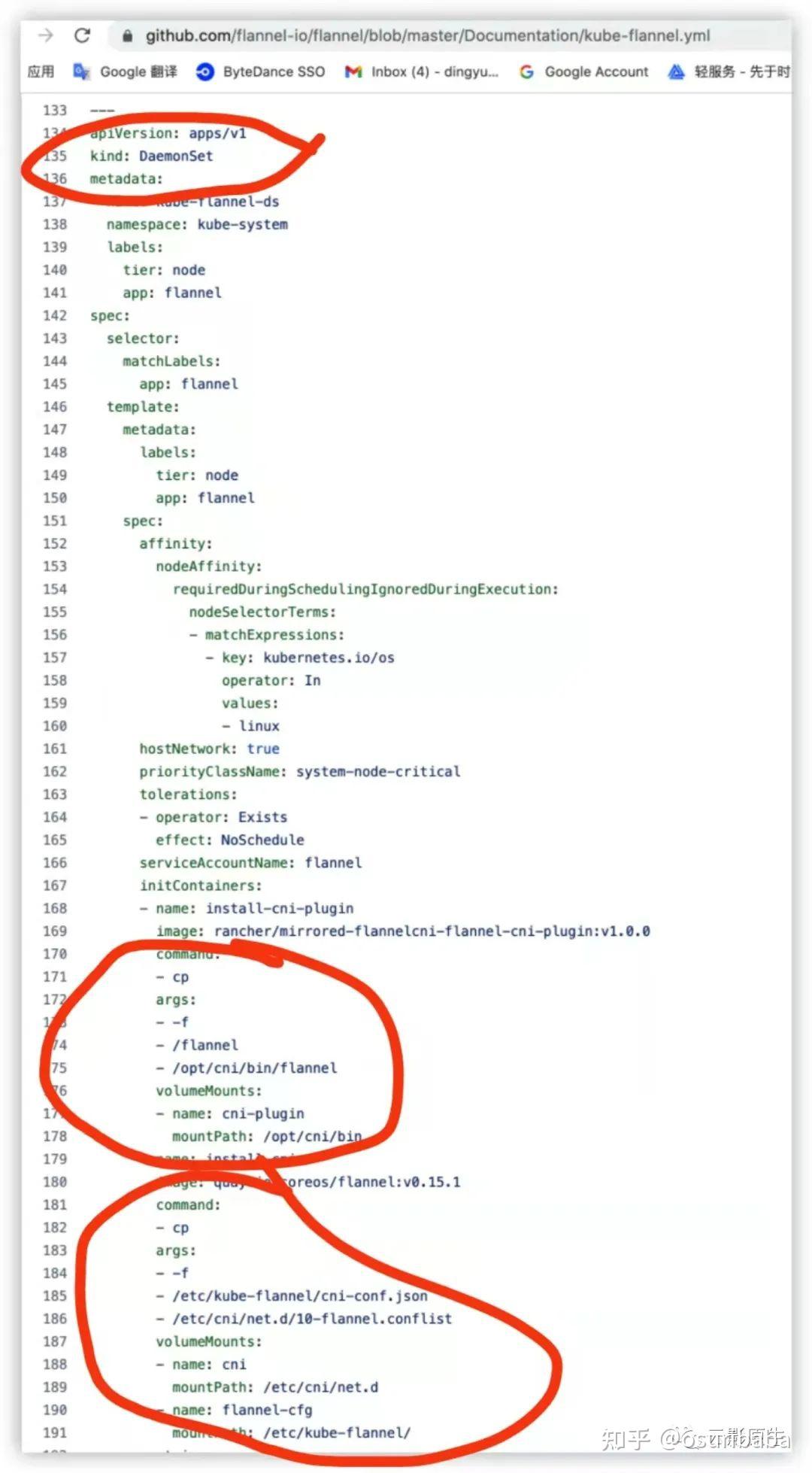
可以看到,这就是一个 DaemonSet,意味着它会被 k8s 给调度到集群中的每一个节点上,而它里面主要做的事情也非常简单,就是用 volume 做路径的映射,然后执行两条 cp 命令,分别把配置文件和创建网络相关的可执行二进制文件给 copy 到主机的 /etc/cni/net.d 和 /opt/cni/bin 两个目录下。然后在适当的时机,k8s 就会自动去读取配置文件,然后根据配置文件中的 “type” 字段,去 /opt/cni/bin 目录下找对应名字的二进制文件然后直接给 exec 咯。
所以综上所述,CNI 规范其实是个非常简单的规范,总结一下就是要求第三方插件需要有一个配置文件,然后有个自己实现创建网络环境的功能二进制,最后 k8s 帮你调用这个插件并把容器的一些运行时环境传过去。就这么简单~
四、CNI 的调用流程
首先上面我们提到了 CRI 规范要走个 containerd,然后 containerd 要调用 OCI 是吧,这里我们先简单看下 containerd 的源码的一小小小部分,以此先来佐证一下上面我们所说的:
1 | // github.com/containerd/containerd/pkg/cri/server/sandbox_run.go |
剔除掉了一些部分,只留下有用的(凑合能看懂的)部分。其主要逻辑就是:
- 创建一个 sandbox 结构体,里面描述了这个 sandbox 的各种信息
- 拉它的镜像
- 生成 oci 的 runtime,这里的 oci 大部分情况下就是 runc,当然也可以使用其他 oci
- 然后生成 netns,设置网络
- 把这些网络塞给 sandbox
- 设置 sandbox 的文件系统
- 用 OCI 拉起 pod
- 逻辑还是蛮清晰的,这里我们解释一下 sandbox 是个啥。
首先 sandbox 是 CRI 规范中的一环,CRI 规范规定了容器启动之前必须要有个 sandbox。sandbox 我们可以理解为沙箱,这个沙箱的作用是什么呢,其实就是为了整合网络资源和存储资源。
我们知道容器可以自己拥有自己的网络,因为容器其实也只是利用 linux 的 namespace 功能抽象出来的隔离,namespace 就可以设置单独的 net ns,docker 中就是如此。但是在 k8s 中,我们不感知“容器”,能感知到的最小单位叫做 “Pod”,为什么要这样做呢?
其实 k8s 作为一个平台,应该是本着包罗万象的愿景而发展的,自然是希望可以在底层对接多种容器技术,docker 也只是其中一种,因此使用 Pod 这个概念来以此屏蔽底层的容器的概念,这样利于平台的发展。
另外还有一点,假设我们只使用容器这个概念,那么每启动一条容器,就要给它设置网络资源,以及设置存储资源,如果该容器挂了十次,那么重启十次就要重复设置十次网络以及十次存储资源,那有没有更好的方法能让容器挂掉重启之后不那么频繁的创建资源呢?诶,有滴,就是把一个或多个容器抽象成一个个的 Pod,让在同一个 Pod 里的容器去共享这一条 Pod 中的网络资源和存储资源(cgroup 之类的资源不共享),这样容器挂了十次,但是只要 Pod 不挂,那它里面的网络资源或者存储资源就还在,下次新创建的 pod 只需要简单地加入进去就可以享用资源了。
那么回到上面说的 sandbox,其实 sandbox 就是刚刚所说的网络资源以及存储资源的承载。我们可以简单地把它理解成,这个 sandbox 就是一个容器,它在 k8s 里被叫做 “pause”,我们可以简单看下 k8s 默认的 pause 容器是啥:
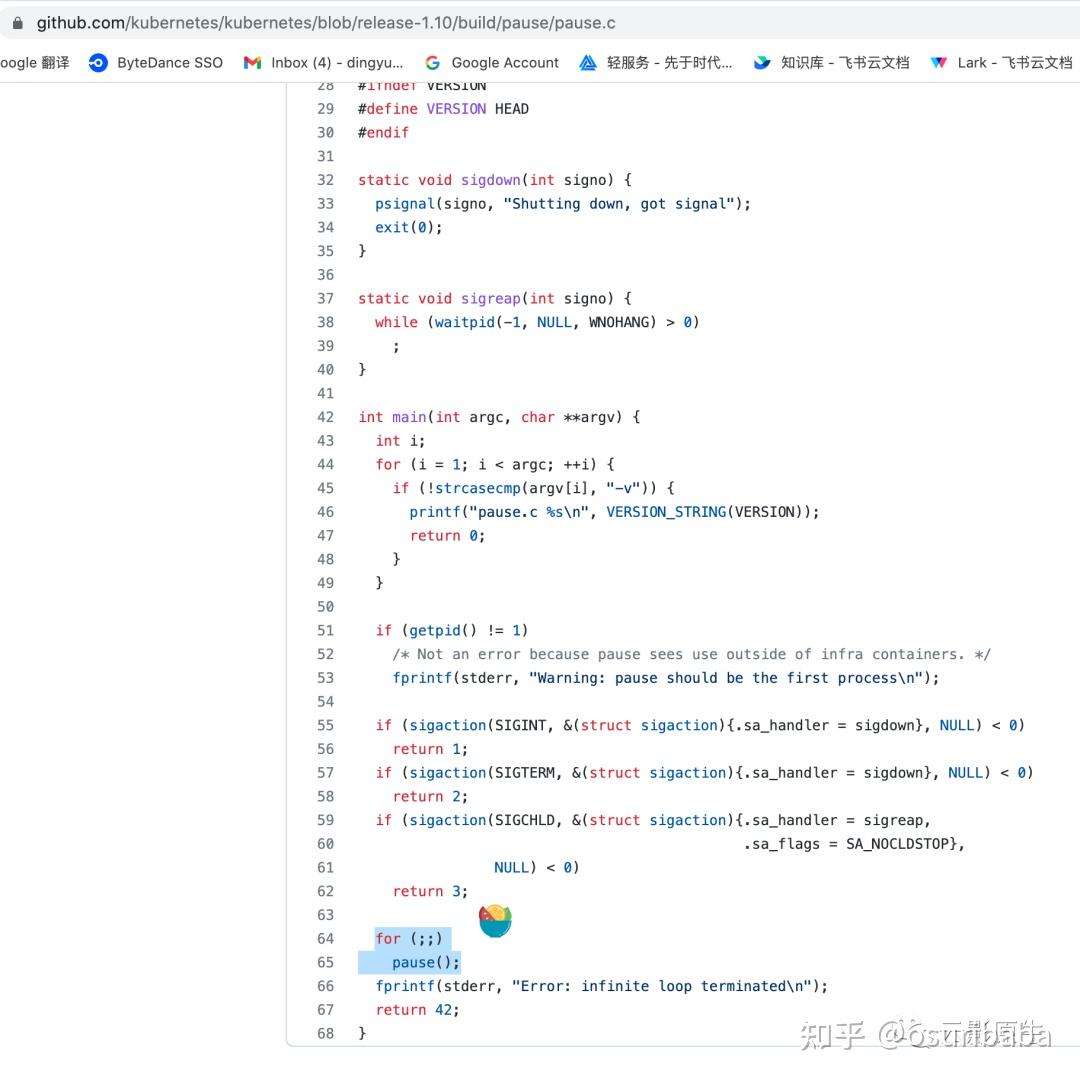
它是一段 c 代码,代码的作用很简单,就是单纯地死循环 pause 方法,该方法是让程序直接陷入睡眠,也不消耗 cpu。
也就是说,这 pause 是一个极度稳定的一条进程,k8s 把这个 pause 容器作为一个 pod 启动之前的 sandbox,具备启动快切稳定的特点,然后把创建的网络资源存储资源等挂到这个 pause 容器里头,然后等 pod 中的其他容器启动后再和这个 pause 共享网络和存储,这样就避免了重复创建网络和存储资源了。
所以了解了 CRI 会将创建的网络资源都加入到 sandbox 之后,我们就可以去看一看 OCI 是如何通过调用插件将网络设置给 sandbox 的了。
这里我们不直接看 OCI 的源码了,在 k8s 官方的 cni repo 中(https://github.com/containernetworking/cni/tree/master/cnitool) 有一个 cnitool 目录,该目录下是一个很简单的 go 文件,里面主要就是模拟了一个网络插件是如何被调用的,我们可以通过学习这个文件来了解 CNI 网络插件被调用的过程:
1 | func main() { |
该文件主要流程较为简单:
- 获取一些环境变量
- 获取网络插件配置(从 /etc/cni/net.d)
- 获取网卡名(这个网卡名会交给 CNI 网络插件, 网络插件中会把这个名字作为每个 pod 里的默认网卡, 默认就叫 eth0)
- 获取 netns(这个就是在 containerd 中生成的属于这条 pod 的网络命名空间, 不过在 cnitool 中是从命令行参数中获取的, 想通过 cnitool 测试网络插件就得自己先创建一个 netns 然后作为参数传进来)
- 生成 containerID
- 生成容器运行时的相关信息
- 根据命令行参数来判断,调用 Add 还是 Check 还是 Del,这里以 Add 为例,cni 这个 repo 的主要代码的 AddNetworkList 方法(在 CRI 中也会调用这个 repo 的这个方法)
- 可以看到这个 AddNetworkList 接收的参数主要就是 netconf 和 rf 俩, 其中 netconf 是从 /etc/cni/net.d 中读取出来的每个插件自己 copy 过去的配置文件, rt 是容器的运行时信息, 这些运行时信息在 cnitool 中是瞎创建的, 在 k8s 中由 CRI 创建
1 | func (c *CNIConfig) addNetwork(ctx context.Context, name, cniVersion string, net *NetworkConfig, prevResult types.Result, rt *RuntimeConf) (types.Result, error) { |
- 顺着 AddNetworkList 往下看, 其实最终就是把从 opt/cni/bin 下拿到的二进制文件给 exec 一下
- 把容器运行时的信息, 包括 containerId, netns path, 网卡设备名字等作为环境变量, 然后还再把从 /etc/cni/net.d 中读取到的以及上一次执行的插件结果(上面说过插件可以是个 list)作为标准输入
- 这样实现 CNI 插件的人在插件代码中就可以通过这两种方式去获取一些必要的信息了
- 最后执行完毕后回到 cnitool 中:
1
2
3
4
5
6case CmdAdd:
result, err := cninet.AddNetworkList(context.TODO(), netconf, rt)
if result != nil {
_ = result.Print()
}
exit(err) - 可以看到拿到了 result 之后直接 Print 了, 也就是说把插件执行结果作为标准输出了, 之后 CRI Runtime 就可以通过标准输出上的东西拿到插件执行结果从而进行一些后续操作
五、总结
最后简单总结一下 CNI 相关。
- k8s 的 kubelet 在启动一个容器之前,会先做一些预先检查以及 csi 的操作
- 然后 kubelet 调用 CRI 的接口,通过 grpc 的方式和 CRI runtime 通信,告知 CRI 要创建 pod 了
- 随后 CRI 的 Server 端收到通知后调用 OCI 的接口去真正的执行拉起 Pod 的操作
- 不过在真的拉起 pod 之前,会先给 pod 创建一个 pause 容器,这个 pause 容器是一个特别小又特别稳定的进程,主要用来挂载网络命名空间和存储资源
- 然后 CRI 调用 CNI 提供的接口,先在 /etc/cni/net.d 目录中获取网络插件配置(这个配置由每个插件自己通过 daemonset 的方式拷贝到主机上), 然后把插件的配置作为标准输入, 再把容器的运行时信息作为环境变量, 最后执行插件
- CNI 插件执行完毕后, 把执行结果(结果要包含一些关键信息比如 Pod IP 等)直接干到标准输出上
- CRI 从标准输出上读取插件执行结果再做后续操作, 后续操作就是拉起真正的容器等