深度干货|云原生分布式数据库 PolarDB-X 的技术演进
/ / 点击 / 阅读耗时 17 分钟一、PolarDB-X是什么
PolarDB-X最早起源于阿里集团2009年提出用分布式架构替代传统商业数据库,阿里研发了TDDL分库分表中间件。2014年阿里集团开始全面上云,将TDDL升级成DRDS分布式数据库服务,实现了在线扩缩容以及数据拆分等能力。2018年后,国内分布式数据库技术进入一个百家争鸣的局面,阿里在这方面也做了很多探索,经过对X-DB、PolarDB等技术整合,诞生了PolarDB-X。

PolarDB-X结合了Sharding On MySQL、NewSQL、Cloud Native DB几种数据库理念的精华,具有云原生分布式的特性,底层使用了PolarDB云原生数据库的技术,上层用到了很多分布式技术。
二、PolarDB-X 技术架构
PolarDB-X采用经典的两层架构,分计算层和存储层。计算层用的PolarDB-X,可以独立水平扩展、扩缩容,各种能力完备。在整个系统里,一条SQL经过自研的解析器、优化器,得到分布式的执行计划;然后发送到存储节点执行;在中间的网络传输层,使用了定制的RPC协议,效率远高于传统的JDBC协议;之后执行计划会发送到PolarDB-X的执行引擎里去做具体的计算。
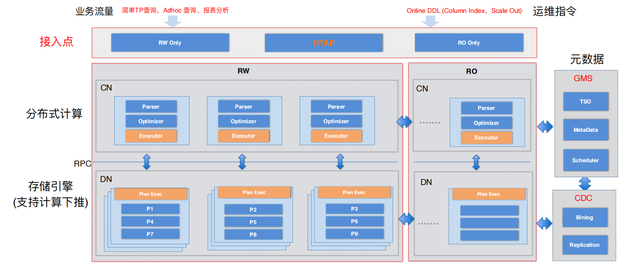
PolarDB-X目前具有高可用、高可扩展、极致弹性等几个特性,高兼容、HTAP、开放生态,在MySQL生态里是一款具有竞争力的产品。
三、PolarDB-X的几个关键技术
(一)分布式事务,如何实现ACID?
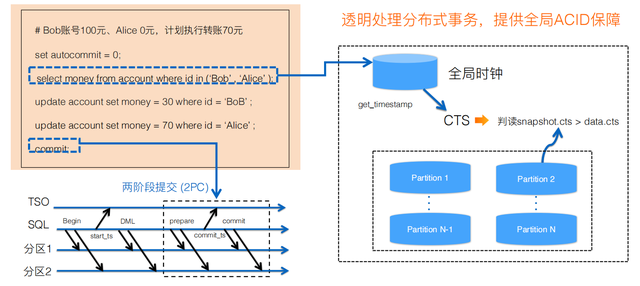
如果分布式数据库要支持金融转账场景,就必须支持分布式事务,才能保证一致性,不会发生数据丢失等异常。纵观业界技术,可以归成以下几类,第一类是基于MySQL的XA技术,实现两阶段提交;缺点是不能保证全局一致,不能保证全局快照。第二类是TSO技术做全局分配,实现给全局的事务定序,从而实现分布式快照。第三是HLC技术,也存在一定的局限性。第四类是在PG里比较多使用的GTM技术。这几项技术目前没有一个能完美解决所有场景,都需要在性能、可用性、扩展性方面去做权衡。PolarDB-X认为TSO是比较契合公有云以及混合云的技术。
PolarDB-X基于TSO技术实现全局分布式事务。第一个问题是如何去做全局时钟,也就是TSO。TSO会给分布式事务做定序,按照时间戳的顺序去做排序。第二个问题是如何基于MySQL的InnoDB做分布式事务。PolarDB-X对InnoDB的事务系统做了深度改造,从原本的ReadView的事务机制改造成基于时间戳的事务系统。有了基于时间戳的事务系统之后,结合TSO技术,就可以实现全局一致的分布式事务。除此之外,事务里还有很多的技术难点,如何处理长写事务以及做全局的垃圾回收。
用TSO技术有一个必须要解决的问题——通常会增加几十微秒到几百微秒的RT。因此,PolarDB-X实现了一阶段提交、2PC的异步提交等优化,能够尽量克服TSO带来的性能损失。
实现上述性能优化之后,经过与业界产品在sysbench和TPCC等测试集做了性能对比,PolarDB-X的性能相对来说非常有竞争力。
(二)透明分布式,如何优化易用性?
透明分布式主要解决的问题是分布式数据库的使用门槛。很多分布式数据库技术听起来很好,但用户却认为很难用。比如用户常常困扰,为什么某些场景的性能会不如一个单机系统,或者某些功能不具备,或者问题难以排查?从我们对服务用户的经验来看,用户在使用分布式数据库过程中通常会遇到以下几个门槛,即如何选择拆分键、如何优化分布式事务、如何优化慢查询。因此,我们研发了透明分布式的项目,试图降低用户使用分布式数据库的门槛。
第一,如何做Sharding。每个产品都有不同的解决方案,PolarDB-X结合了MySQL分区表语法,从语法上完全兼容MySQL列表,使用二级分区覆盖到用户的各种Workload。这背后是基于一致性哈希算法,实现分区级的动态分裂,大大降低扩缩容的代价。以Range分区为例,一开始可能是4千到5千这个数据范围,当这个Range的数据变多之后,它可以分裂成多个Range,迁移到多个机器上,避免数据过于集中。将这些技术融入PolarDB-X中,能够有效解决热点数据等问题。
第二,PolarDB-X做的跟其他产品有差异化的技术,是TableGroup。它解决的问题是Join下推,这是阿里的业务场景中非常常见。如果不能做Join的下推,做分布式Join的性能会比较差。在PolarDB-X中,多个表按一个分区方式做Partition,它们就会放置于同一个TableGroup,因此就可以实现Join下推。当然对应的,一个TableGroup中的分区分裂、迁移,都需要以PartitionGroup为单位了。
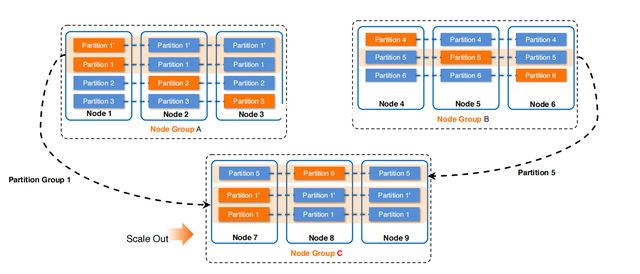
第三,扩缩容离不开的一个问题,就是Online DDL。例如PolarDB-X支持单表、拆分表、分区表,当用户对表类型进行修改,把分区键从买家ID改成卖家ID的时候,背后就是用Online DDL的技术。PolarDB-X支持多种的Online DDL,包括拆分键修改、创建索引、加减列等等,这些操作都可以在线上直接执行,对用户业务影响非常小。
PolarDB-X的透明分布式提供了分区表、全局索引、Online DDL等技术,使得用户的业务能够以很低的成本接入到分布式数据库中,并且后续随着业务的发展,数据库还可以做通过Scale-Up或者Scale-Out的方式提高性能。
(三)HTAP技术,如何提高分析能力
所谓HTAP,在PolarDB-X的理解中,即能否在线上数据库中执行复杂查询。它的价值有两方面,一方面是能够降低用户的使用成本、运维成本,另一方面,就是实时的分析,能够从实时数据获得实时洞察。做HTAP面对的技术挑战有几方面,分别是负载隔离、计算能力、存储能力。
对应到PolarDB-X的架构,会通过只读节点做负载隔离,简单查询发到读写节点,复杂查询发到只读节点执行,因此这两种负载能够得到较好的隔离,不会相互影响。这中间的智能路由是通过优化器的代价估算去实现,代价高的判定为AP查询,代价低的判定TP查询。除此之外,这种架构还需要解决的一个问题是一致性快照,PolarDB-X通过TSO技术,实现了只读节点的分布式事务。
接下来的问题是如何提升计算能力和存储能力。
提高计算能力主要通过MPP并行计算、向量化计算等方式。此前PolarDB-X主要面向TP场景,做算子下推,以及通过分区裁剪尽量查询更少的分片,优化TP场景的性能。而面对AP场景,需要的技术则很不一样。具体来说,PolarDB-X提供了原生的MPP支持,能够充分发挥多个节点的资源进行计算。为此,优化器里中增加了MPP优化阶段,在单机执行计划之后,中间加入Exchange,变成分布式的执行计划,实现多机并行。具体到执行器,也会有两种执行模式,一种是本地单机执行,另一种是MPP分布式执行。
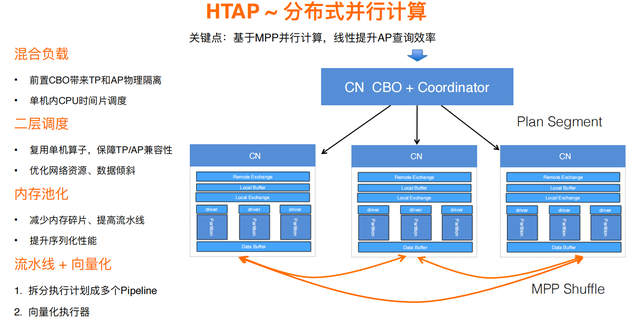
具体来看,在MPP并行计算中,PolarDB-X做了两层的并行,第一层是节点之间的并行,第二层是计算节点内部的运行。分为两层的好处在于能够减少调度开销,减少数据传输的开销。除此之外,PolarDB-X还做了内存池化、流水线化、向量化等精细化的技术,通过向量化提高执行器的执行效率,通过流水线化增加并行度减少数据物化。这些技术使得PolarDB-X在执行复杂SQL查询时具有较高的效率。
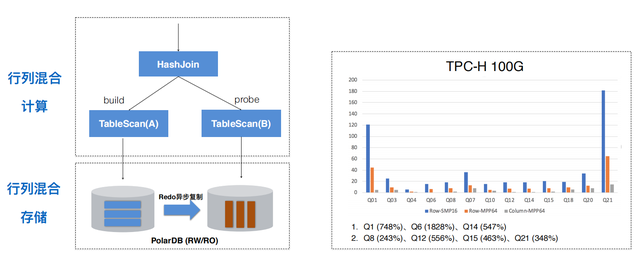
除此之外,就是提高存储方面的性能。从技术角度看,单独做一个行存、列存都不难,难的是做一个能够实时更新的列存。PolarDB-X采用的方案是在写入节点用行存,在只读节点用列存,中间通过redo做异步复制,实现列存的实时更新。基于这样的架构,就可以实现行列混存,行存承担高并发写入,列存承担复杂查询。结合MPP、行列混存、向量化等技术,PolarDB-X实现了TPC-H场景的5-10倍的性能提升。这一成果也即将在公有云上线,敬请期待。
四、总结
PolarDB-X能够高度兼容单机MySQL,从SQL兼容到事务兼容到生态兼容。在此基础上,通过透明分布式的技术降低用户使用门槛,使得用户可以快速上手,适配各种用户业务,并通过弹性扩缩容的能力,适应用户的业务变化。而HTAP技术,将形成差异化的竞争力,使得用户能够从在线数据中获得实时洞察。