大新闻 | Snowflake 和 Databricks 为夺 PG 再次大打出手!
/ / 点击 / 阅读耗时 6 分钟为了争 PostgreSQL生态, Snowflake 和 Databricks 大打出手
PG真的这么香吗? 为了争 PostgreSQL 生态, Snowflake 和 Databricks 又打起来了?
这不对啊, 为什么国内PG没什么人用? 也不多招聘需求啊!
我敢拍胸脯说, 国内大多数人第一次听说PostgreSQL, 可能是因为国产化, 因为很多数据库套壳PG!
近期可能还由于AI的兴起, 一部分传统关系数据库用户可能因为pgvector开始接触到PG.
国外则不一样, 看DB-Engein就知道, 很多年以前, PG的发展就是一路飙升, 多年以前一直是开发者最喜爱和最想用两个维度的第一.
如果你不能直接感知到PG在国外有多火, 从两家著名的数据库上市公司Snowflake和Databrick的收购行为即可窥透一切!
近期, 为了争 PostgreSQL 生态, Snowflake 和 Databricks 又打起来了!
故事要从收购说起,
《德说-第333期, Databricks花10亿美元买开源Neon数据库, 值得吗?》 这篇文章说了前后脚的两起收购: Databrick 10亿美金收购PG商业发行版Neon Database, Snowflake 2.5亿美金收购PG商业发行版Crunchy Data!
Neon和Crunchy都是PostgreSQL的云服务提供商, 也是PostgreSQL的核心贡献者Hikki和Tom Lane所在的2家公司.
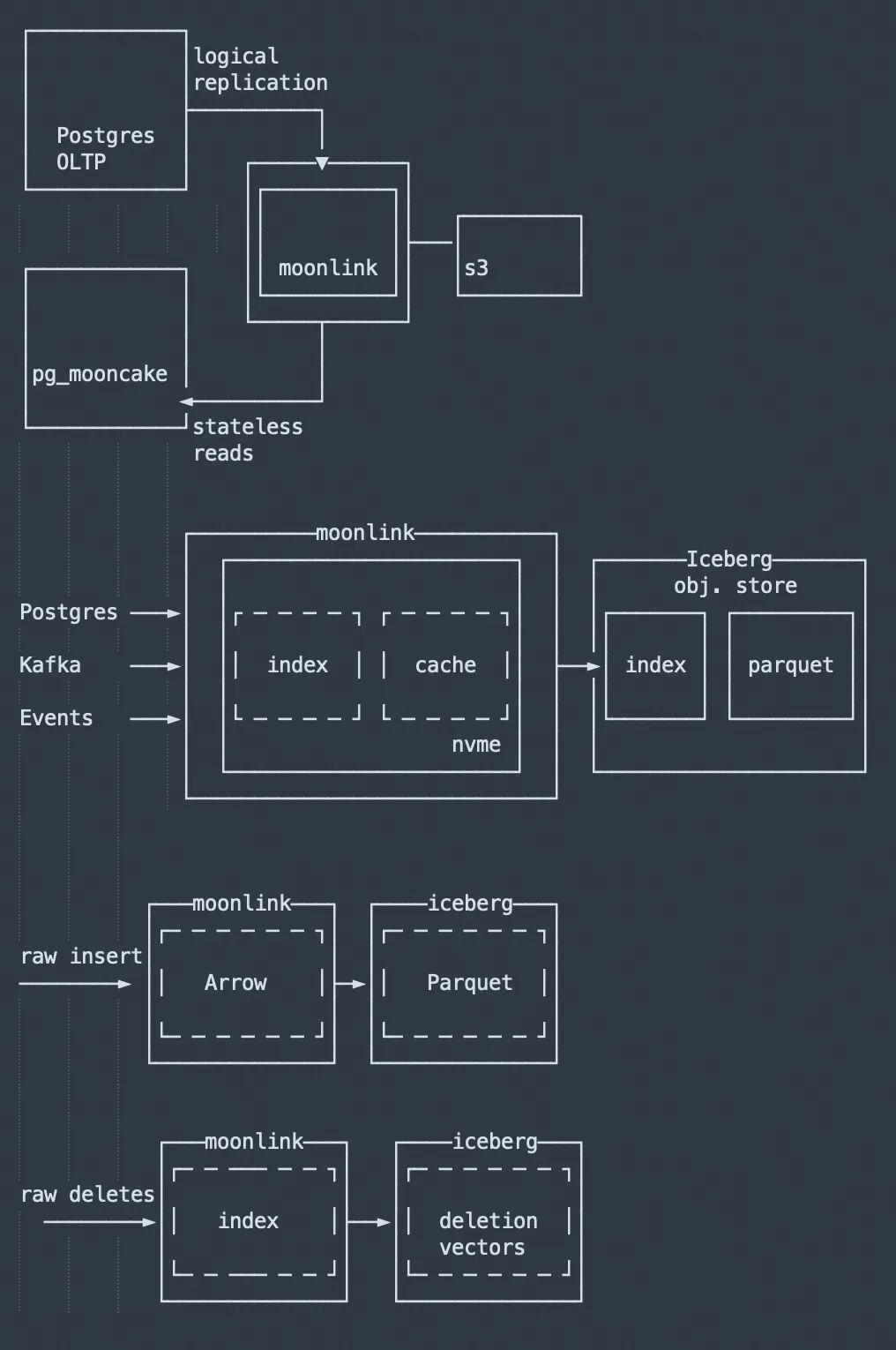
紧随其后, Databrick又干了一票:《大新闻 | Databricks收购Mooncake, 补齐AI Agent实时数据管道短板》
Mooncake和CrunchyData的功能有点类似, 都是结合了duckdb的算力, 对象存储和iceberg/parquet等存储文件, 给PG加上数据湖(实时分析)的翅膀. 可参考阅读:《内置列存储 vs 传统 ETL: pg_mooncake 与 CrunchyData 打起来了》
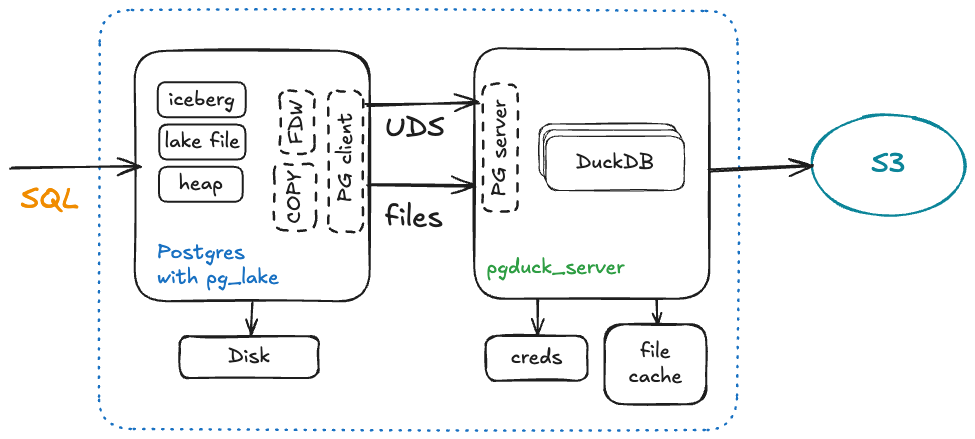
Mooncake Labs被Databricks收购后, Snowflake也没闲着, 就在前几天, CrunchyData开源了pg_lake等一系列插件, 这系列插件可以让开源PG用户直接获得DuckDB的算力, 实时与Iceberg/对象存储的交互能力, 在对象存储的数据可写可读. ( https://www.snowflake.com/en/engineering-blog/pg-lake-postgres-lakehouse-integration/ )
你可以看看moonlink和crunchydata提供的架构, 简直一毛一样, 只是moonlink还多做了一点: pg逻辑订阅+实时管道入湖, 我个人认为moonlink对PG用户的意义更大.
两者架构对比如下, 你觉得谁家的略胜一筹?
Snowflake 和 Databricks 为什么这么看重PostgreSQL生态? 很简单, PG的用户体量大(而且还在向上发展). 作为云数据库厂商, 你觉得他的核心是什么?
第一步, 当然是把数据存进来,
第二步, 让用户对数据进行不断的计算挖掘.即可以赚存储的钱, 又可以赚计算的钱.
第三步, 再结合AI, 还可赚深度分析的钱( 这个价值无法估量. 打个比方: 如果你问他明天那支股票会涨, 成功概率有90%, 你觉得你会花多少钱买这个消息? ) 这么说起来这两家应该还会投一些做数据挖掘/模型训练的公司?
- 当然, 如果要跨用户访问其他用户数据, 这个事就关系到数据资产的归属, 不容易干, 否则就是偷盗用户数据了! 目前仅仅是美好想象而已
Snowflake 和 Databricks 争夺PG生态, 目的是数据!因为 PG 真香, 只是国内绝大多数用户有眼不识好货!
争夺还没有停止! 看着吧!
你有什么看法? 欢迎留言!