一、前言 在上一篇玩一玩系列——玩玩pg_duckdb(我的开源之旅) 文章中,我们有讲到pg_duckdb对于SELECT语句的一个较为详细的处理流程,大概能了解到pg_duckdb是如何加速查询效率的(甚至在某些场景之下,获得上千倍的提升不在话下),
同样也知道了它的加速是有限制的,其限制的瓶颈点在于它需要将PostgreSQL中的行存储的数据一行一行的转换填充之duckdb的列存之中(实话实话,这成本过于高昂),所以当且仅当这个加载数据转换的时间和原本查询的时间越显得不值一提的时候,实际加速的效果就越好。
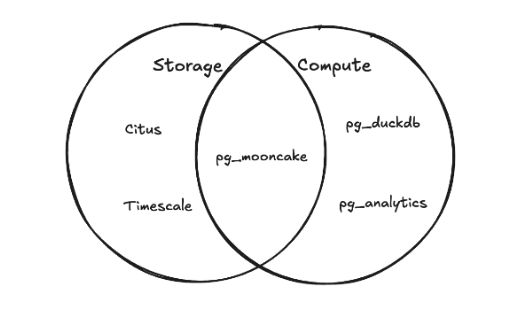
依旧是在上篇文章中,我有讲到pg_duckdb的技术路线是Custom Scan,但其实并不仅仅是Custom Scan,它也实现了TAM(Table Access Method),只不过限制仅支持临时表,所以我也没有多少想讲的意愿,而是留给今天的主角pg_mooncake。
pg_mooncake是在pg_duckdb上构建的,相对而言是青出于蓝而胜于蓝,因为它涵盖了pg_duckdb,所以它的技术路线也包括了Custom Scan,不过它在TAM(Table Access Method)方面做的更好,它不再局限于临时表的同时,给PostgreSQL带来了真正的列式存储。
这里我称呼它为PostgreSQL的列存新贵的原因在于:在它之前,其实就存在列式存储插件,因为要想AP跑的好,列式存储少不了,其实有了列存也还不够,计算方面也得跟上。
所以在pg_mooncake的前面还有些”老前辈”,比如说 hydradatabase(现在在整pg_duckdb的那位)的开源项目columnar ,
加速效果也有,但是效果不是那么理想。但是它也解决了不少问题,比方说是数据压缩,因为列式存储在压缩上具有天然的优势,可以做到较高的压缩率,节省空间。
伴随着时代的进步,duckdb的出现,从而出现了更加优秀的列式存储插件pg_mooncake,还是非常值得高兴的。
关于TAM(Table Access Method)相关资料请参考PostgreSQL的官方文档https://www.postgresql.org/docs/16/sql-create-access-method.html 。
二、Mooncake Labs团队 在正式玩起来之前呢,我想先简单介绍一下pg_mooncake的技术团队,毕竟我和他们团队的cc大佬还算是挺聊的来、也蛮有缘的(虽然我总是因为有事情要忙,以至于经常咕咕咕人家🕊🕊)。
pg_mooncake是由Mooncake Labs团队打造的一个开源项目,而Mooncake Labs是坐落在美国旧金山的一支技术非常NB的团队。
他们中大多数的成员都来自海外的一家名为SingleStore的公司,如果大家对这家公司有过了解的话,应该能大概知道这家公司在海外HTAP还是算挺有名气的。
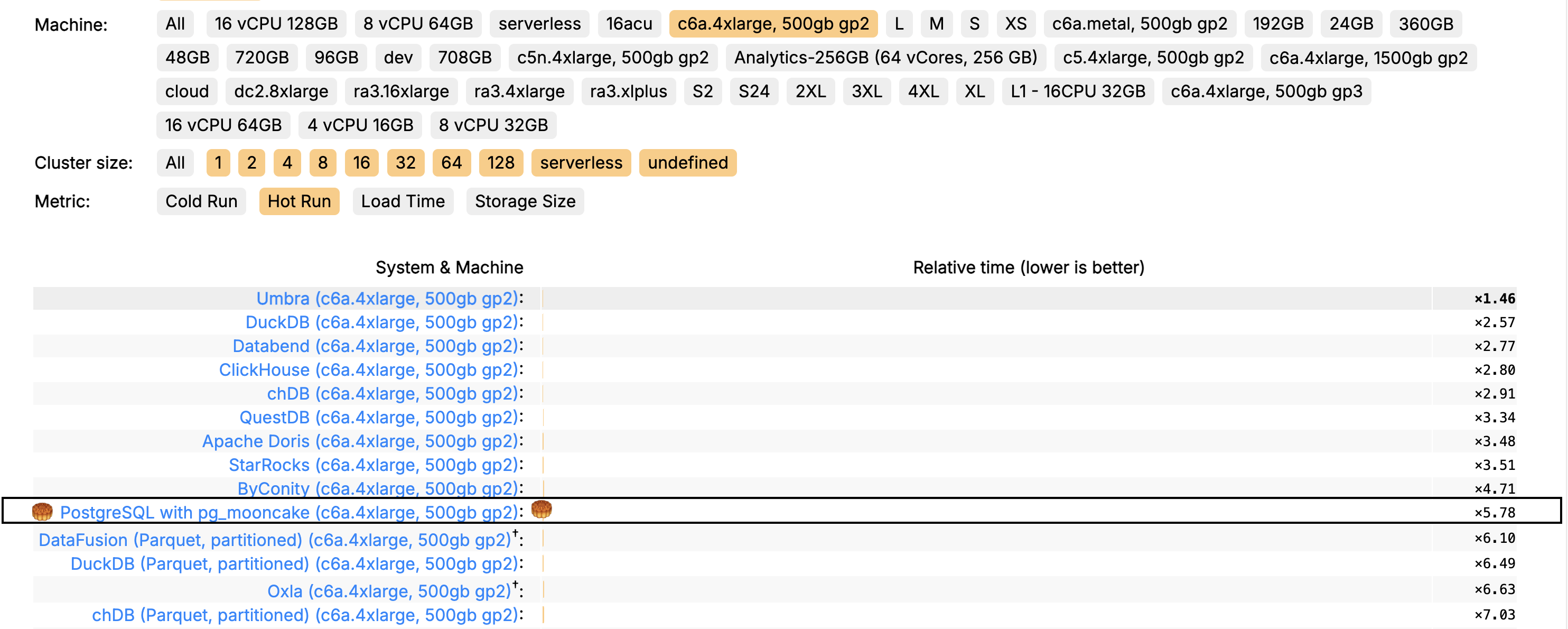
因此Mooncake Labs团队中的成员也积攒了大量关于这方面的经验,这可能也是他们能把pg_mooncake优化到ClickBench前10的一个原因吧(虽然现在可能降了一点,但是无伤大雅)。
(这是之前的记录图片)
他们团队也是正在招人(有挺多的方向,这里我只提一嘴数据库内核方向),感兴趣的同学可以去试试。
官网主页:https://pgmooncake.com/
招聘信息:https://mooncakelabs.notion.site/build-the-mooncake-11cb7b68b5c1802a84a9e21649f49477
三、pg_mooncake 接下来进入正篇,让我们走进pg_mooncake。
github项目地址:https://github.com/Mooncake-Labs/pg_mooncake
还是以源码安装为例、可参考https://github.com/Mooncake-Labs/pg_mooncake/blob/main/CONTRIBUTING.md
1 2 3 4 5 6 7 8 9 10 11 12 cd $PostgreSQL 源码目录/contribgit clone https://github.com/Mooncake-Labs/pg_mooncake.git cd pg_mooncake/git submodule update --init --recursive make debug make install
和pg_duckdb不同的是在使用上pg_mooncake不需要设置shared_preload_libraries,直接连接数据库,创建拓展即可。
1 CREATE EXTENSION pg_mooncake;
3.1、简单罗列一下相关参数 和pg_duckdb相比,pg_mooncake的参数则是要少的多,很清爽(毕竟pg_duckdb要带货)。
如果只是简单体验体验的话,就默认设置什么都不动就可以了。这里简单罗列一下相关参数信息:
name
short_desc
mooncake.allow_local_tables
Allow columnstore tables on local disk
mooncake.default_bucket
Default bucket for columnstore tables
mooncake.enable_local_cache
Enable local cache for columnstore tables
mooncake.enable_memory_metadata_cache
Enable memory cache for Parquet metadata
mooncake.maximum_memory
The maximum memory DuckDB can use (e.g., 1GB)
mooncake.maximum_threads
Maximum number of DuckDB threads per Postgres backend
上面我们有说过pg_mooncake是将pg_duckdb糅合在一起,那可能有的朋友就很好奇,可能会提出这样子的疑问就是说那么pg_duckdb的参数在pg_mooncake中是否有效呢?
答案是无效的,让我们简单看一下pgmooncake.cpp中的_PG_init就一目了然了
1 2 3 4 5 6 7 void _PG_init() { MooncakeInitGUC (); DuckdbInitHooks (); DuckdbInitNode (); pgduckdb::RegisterDuckdbXactCallback (); }
可以看到pg_mooncake在_PG_init时不初始化pg_duckdb的相关参数,所以pg_duckdb的相关参数自然就无效了。
同时我们可以注意到它调用了pg_duckdb的DuckdbInitHooks、DuckdbInitNode这两个接口(内部实际会有些许改动),
也就是说从代码层面论证了我们在上一篇文章中讲到的内容在pg_mooncake依旧有效。所以实际上来说,什么都不需要设置,创建完拓展之后就可以愉快的玩耍了。
3.2、简单使用 在最开始的时候,我们指出了pg_duckdb的性能瓶颈可能在于将PostgreSQL中存储的行数据转换成duckdb的列数据。并且pg_duckdb仅对SELECT语句进行了额外的处理,对于其他SQL语句而言,如INSERT、UPDATE、DETELE都是交由PostgreSQL处理。
可能是pg_mooncake看到了这些痛点,所以它将INSERT、UPDATE、DETELE等等都给支持了,并在执行这些相关语句的时候,创建对应的Parquet文件,并存储相关数据。
当访问列存表时,对于数据加载那块便仅需要访问对应的Parquet文件即可,就这样避免了pg_duckdb在加载数据时的痛点。
而且物理文件使用Parquet文件作为外部存储,对于构建数据湖也很方便。
以官方的测试案例为例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 [postgres@halo-centos8 mooncake_local_tables]$ psql mooncake psql (16.8) Type "help" for help . mooncake=# \dx List of installed extensions Name | Version | Schema | Description -------------+---------+------------+------------------------------- pg_mooncake | 0.1.2 | public | Columnstore Table in Postgres plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language (2 rows) mooncake=# -- 创建列存表 mooncake=# CREATE TABLE user_activity( mooncake(# user_id BIGINT, mooncake(# activity_type TEXT, mooncake(# activity_timestamp TIMESTAMP, mooncake(# duration INT mooncake(# ) USING columnstore; CREATE TABLE mooncake=# -- 通过explain来简单判断INSERT是否被支持 mooncake=# EXPLAIN VERBOSE INSERT INTO user_activity VALUES mooncake-# (1, 'login' , '2024-01-01 08:00:00' , 120), mooncake-# (2, 'page_view' , '2024-01-01 08:05:00' , 30), mooncake-# (3, 'logout' , '2024-01-01 08:30:00' , 60), mooncake-# (4, 'error' , '2024-01-01 08:13:00' , 60); QUERY PLAN -------------------------------------------------------------------- Custom Scan (MooncakeDuckDBScan) (cost=0.00..0.00 rows=0 width=0) Output: duckdb_scan.explain_key, duckdb_scan.explain_value DuckDB Execution Plan: ┌───────────────────────────┐ │ COLUMNSTORE_INSERT │ └─────────────┬─────────────┘ ┌─────────────┴─────────────┐ │ COLUMN_DATA_SCAN │ │ ──────────────────── │ │ ~4 Rows │ └───────────────────────────┘ (14 rows) mooncake=# -- 插入数据 mooncake=# INSERT INTO user_activity VALUES mooncake-# (1, 'login' , '2024-01-01 08:00:00' , 120), mooncake-# (2, 'page_view' , '2024-01-01 08:05:00' , 30), mooncake-# (3, 'logout' , '2024-01-01 08:30:00' , 60), mooncake-# (4, 'error' , '2024-01-01 08:13:00' , 60); INSERT 0 4 mooncake=# -- 查询数据 mooncake=# SELECT * from user_activity; user_id | activity_type | activity_timestamp | duration ---------+---------------+---------------------+---------- 1 | login | 2024-01-01 08:00:00 | 120 2 | page_view | 2024-01-01 08:05:00 | 30 3 | logout | 2024-01-01 08:30:00 | 60 4 | error | 2024-01-01 08:13:00 | 60 (4 rows) mooncake=# -- 查看列存表对应物理文件位置 mooncake=# SELECT * FROM mooncake.columnstore_tables; table_name | path ---------------+------------------------------------------------------------------------ user_activity | /data/16/mooncake_local_tables/mooncake_mooncake_user_activity_279647/ (1 row)
如果你按照我的操作来进行的话,这个数据目录不一定和我这里一样,这个目录的命名规则为$PGDATA/mooncake_local_tables/mooncake_数据库名_表名_表oid
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 string ColumnstoreMetadata::GetTablePath (Oid oid) { ::Relation table = table_open (oid, AccessShareLock); string path = StringUtil::Format ("mooncake_%s_%s_%d/" , get_database_name (MyDatabaseId), RelationGetRelationName (table), oid); table_close (table, AccessShareLock); if (mooncake_default_bucket != nullptr && mooncake_default_bucket[0 ] != '\0' ) { path = StringUtil::Format ("%s/%s" , mooncake_default_bucket, path); } else if (mooncake_allow_local_tables) { path = StringUtil::Format ("%s/mooncake_local_tables/%s" , DataDir, path); } else { elog (ERROR, "Columnstore tables on local disk are not allowed. Set mooncake.default_bucket to default " "S3 bucket" ); } return path; }
而对应的parquet文件的命名则是非常明显的uuid
1 file_name = UUID::ToString (UUID::GenerateRandomUUID ()) + ".parquet" ;
让我们看一下/data/16/mooncake_local_tables/mooncake_mooncake_user_activity_279647/这个目录存在哪些东西,
1 2 3 4 5 6 7 8 9 10 11 [postgres@halo-centos8 mooncake_local_tables]$ tree /data/16/mooncake_local_tables/mooncake_mooncake_user_activity_279647/ /data/16/mooncake_local_tables/mooncake_mooncake_user_activity_279647/ ├── 721e8499-b4c3-4a4a-a822-5af1fc45e237.parquet └── _delta_log ├── 00000000000000000000.json └── 00000000000000000001.json 1 directory, 3 files [postgres@halo-centos8 mooncake_local_tables]$ cat /data/16/mooncake_local_tables/mooncake_mooncake_user_activity_279647/_delta_log/00000000000000000001.json {"add" :{"path" :"721e8499-b4c3-4a4a-a822-5af1fc45e237.parquet" ,"partitionValues" :{},"size" :699,"modificationTime" :0,"dataChange" :true ,"stats" :null,"tags" :null,"deletionVector" :null,"baseRowId" :null,"defaultRowCommitVersion" :null,"clusteringProvider" :null}} {"commitInfo" :{"timestamp" :1740987491586,"operation" :"WRITE" ,"operationParameters" :{"mode" :"Append" },"clientVersion" :"delta-rs.0.21.0" }}
这里我们想尝试去读一下721e8499-b4c3-4a4a-a822-5af1fc45e237.parquet,可以用mooncake.read_parquet也可以用duckdb,这里我还是用duckdb来读取
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [postgres@halo-centos8 ~]$ ./duckdb v1.1.3 19864453f7 Enter ".help" for usage hints. Connected to a transient in-memory database. Use ".open FILENAME" to reopen on a persistent database. D select * from read_parquet('/data/16/mooncake_local_tables/mooncake_mooncake_user_activity_279647/721e8499-b4c3-4a4a-a822-5af1fc45e237.parquet' ); ┌─────────┬───────────────┬─────────────────────┬──────────┐ │ user_id │ activity_type │ activity_timestamp │ duration │ │ int64 │ varchar │ timestamp │ int32 │ ├─────────┼───────────────┼─────────────────────┼──────────┤ │ 1 │ login │ 2024-01-01 08:00:00 │ 120 │ │ 2 │ page_view │ 2024-01-01 08:05:00 │ 30 │ │ 3 │ logout │ 2024-01-01 08:30:00 │ 60 │ │ 4 │ error │ 2024-01-01 08:13:00 │ 60 │ └─────────┴───────────────┴─────────────────────┴──────────┘
可以看到和在PostgreSQL中读取到的数据是一致的。
_delta_log中的相关json文件,就是实际对应的事务日志。json文件和parquet文件并不总是线性增长的,如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 [postgres@halo-centos8 ~]$ psql mooncake psql (16.8) Type "help" for help . mooncake=# BEGIN; -- 开启事务块 BEGIN mooncake=*# INSERT INTO user_activity VALUES (5, 'test' , '2024-01-01 08:13:00' , 60); INSERT 0 1 mooncake=*# INSERT INTO user_activity VALUES (6, 'test' , '2024-01-01 08:13:00' , 60); INSERT 0 1 mooncake=*# ROLLBACK; -- 回滚事务 ROLLBACK
让我们再次查看一下/data/16/mooncake_local_tables/mooncake_mooncake_user_activity_279647/的目录结构和json数据
1 2 3 4 5 6 7 8 9 10 11 12 13 [postgres@halo-centos8 ~]$ tree /data/16/mooncake_local_tables/mooncake_mooncake_user_activity_279647/ /data/16/mooncake_local_tables/mooncake_mooncake_user_activity_279647/ ├── 721e8499-b4c3-4a4a-a822-5af1fc45e237.parquet ├── 81d8cb44-0136-4cf6-8188-7a673ad1da92.parquet ├── _delta_log │ ├── 00000000000000000000.json │ └── 00000000000000000001.json └── f7afb9b9-a876-4905-9990-74177f65ee22.parquet 1 directory, 5 files [postgres@halo-centos8 ~]$ cat /data/16/mooncake_local_tables/mooncake_mooncake_user_activity_279647/_delta_log/00000000000000000001.json {"add" :{"path" :"721e8499-b4c3-4a4a-a822-5af1fc45e237.parquet" ,"partitionValues" :{},"size" :699,"modificationTime" :0,"dataChange" :true ,"stats" :null,"tags" :null,"deletionVector" :null,"baseRowId" :null,"defaultRowCommitVersion" :null,"clusteringProvider" :null}} {"commitInfo" :{"timestamp" :1740987491586,"operation" :"WRITE" ,"operationParameters" :{"mode" :"Append" },"clientVersion" :"delta-rs.0.21.0" }}
可以发现json文件没有发生任何变化,但是新增了两个parquet文件,我们再次使用duckdb读取一下此目录中的所有parquet
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 [postgres@halo-centos8 ~]$ ./duckdb v1.1.3 19864453f7 Enter ".help" for usage hints. Connected to a transient in-memory database. Use ".open FILENAME" to reopen on a persistent database. D select * from read_parquet('/data/16/mooncake_local_tables/mooncake_mooncake_user_activity_279647/*' ); -- * 代表所有的parquet ┌─────────┬───────────────┬─────────────────────┬──────────┐ │ user_id │ activity_type │ activity_timestamp │ duration │ │ int64 │ varchar │ timestamp │ int32 │ ├─────────┼───────────────┼─────────────────────┼──────────┤ │ 1 │ login │ 2024-01-01 08:00:00 │ 120 │ │ 2 │ page_view │ 2024-01-01 08:05:00 │ 30 │ │ 3 │ logout │ 2024-01-01 08:30:00 │ 60 │ │ 4 │ error │ 2024-01-01 08:13:00 │ 60 │ │ 5 │ test │ 2024-01-01 08:13:00 │ 60 │ │ 6 │ test │ 2024-01-01 08:13:00 │ 60 │ └─────────┴───────────────┴─────────────────────┴──────────┘
可以看到我们回滚的那两个记录能被查询到,所以实际上那两个parquet分别对应一条INSERT语句。
3.3、行列混存 也正是因为pg_mooncake实现了列式存储,所以对于PostgreSQL而言,便出现了行列混存的情形。
最简单的场景便是构建一张堆表和一张列存表,那么这两张表可以join吗?
答案是可以的。如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 [postgres@halo-centos8 ~]$ psql mooncake psql (16.8) Type "help" for help . mooncake=# CREATE TABLE ta(user_id BIGINT); -- 简单堆表 CREATE TABLE mooncake=# INSERT INTO ta SELECT * FROM generate_series(1, 6); -- 生成六行数据 INSERT 0 6 mooncake=# SELECT * FROM ta Inner Join user_activity on ta.user_id = user_activity.user_id; -- 简单测试查看结果 user_id | user_id | activity_type | activity_timestamp | duration ---------+---------+---------------+---------------------+---------- 1 | 1 | login | 2024-01-01 08:00:00 | 120 2 | 2 | page_view | 2024-01-01 08:05:00 | 30 3 | 3 | logout | 2024-01-01 08:30:00 | 60 4 | 4 | error | 2024-01-01 08:13:00 | 60 (4 rows) mooncake=# EXPLAIN VERBOSE SELECT * FROM ta Inner Join user_activity on ta.user_id = user_activity.user_id; -- 简单测试查看执行计划 QUERY PLAN -------------------------------------------------------------------- Custom Scan (MooncakeDuckDBScan) (cost=0.00..0.00 rows=0 width=0) Output: duckdb_scan.explain_key, duckdb_scan.explain_value DuckDB Execution Plan: ┌───────────────────────────┐ │ PROJECTION │ │ ──────────────────── │ │ user_id │ │ user_id │ │ activity_type │ │ activity_timestamp │ │ duration │ │ │ │ ~2260 Rows │ └─────────────┬─────────────┘ ┌─────────────┴─────────────┐ │ HASH_JOIN │ │ ──────────────────── │ │ Join Type: INNER │ │ │ │ Conditions: ├──────────────┐ │ user_id = user_id │ │ │ │ │ │ ~2260 Rows │ │ └─────────────┬─────────────┘ │ ┌─────────────┴─────────────┐┌─────────────┴─────────────┐ │ POSTGRES_SEQ_SCAN ││ COLUMNSTORE_SCAN │ │ ──────────────────── ││ ──────────────────── │ │ Function: ││ Function: │ │ POSTGRES_SEQ_SCAN ││ COLUMNSTORE_SCAN │ │ ││ │ │ Projections: user_id ││ Projections: │ │ ││ user_id │ │ ││ activity_type │ │ ││ activity_timestamp │ │ ││ duration │ │ ││ │ │ ~2260 Rows ││ ~4 Rows │ └───────────────────────────┘└───────────────────────────┘ (41 rows)
所以显而易见的是,pg_mooncake将数据都加载到了duckdb中,然后去执行了。
对于堆表而言,若当前SQL查询存在列存表,会走原本pg_duckdb的逻辑,会将元组数据转换成duckdb的列数据,对应POSTGRES_SEQ_SCAN。(如果当前查询并不包含列存表,则走的PostgreSQL的默认逻辑)
对于列存表而言,走的则是pg_mooncake自己提供的COLUMNSTORE_SCAN,实际上就是parquet_scan。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 TableFunction ColumnstoreTable::GetScanFunction (ClientContext &context, unique_ptr<FunctionData> &bind_data) { auto file_names = metadata->DataFilesSearch (oid, &context, &path, &columns); auto file_paths = GetFilePaths (path, file_names); if (file_paths.empty ()) { return TableFunction ("columnstore_scan" , {} , EmptyColumnstoreScan); } TableFunction columnstore_scan = GetParquetScan (context); -- 注意此处 columnstore_scan.name = "columnstore_scan" ; columnstore_scan.init_global = ColumnstoreScanInitGlobal; columnstore_scan.statistics = nullptr ; columnstore_scan.get_multi_file_reader = ColumnstoreScanMultiFileReader::Create; TableFunction GetParquetScan (ClientContext &context) { return ExtensionUtil::GetTableFunction (*context.db, "parquet_scan" ) -- 实际是parquet_scan .functions.GetFunctionByArguments (context, {LogicalType::LIST (LogicalType::VARCHAR)}); }
所以pg_mooncake还是设计的蛮巧妙的。欢迎感兴趣的同学可以去点点Star,提提PR。
3.4、不足之处? 这其实到没啥好说的了,我能注意到的必然也逃不过pg_mooncake的大佬的法眼。
一般的都被记录到Issues中了,比方说资源管理之类的,如drop table之后,对应的物理目录及文件未被及时清除之类的;
比如说性能优化之类的,如https://github.com/Mooncake-Labs/pg_mooncake/issues/82
听说cc他们规划后续会将pg_mooncake做成一个基于PostgreSQL的HTAP数据库,让人非常的期待呀。
四、推荐阅读 有意思的是pg_mooncake虽然使用的是duckdb的parquet功能,但是在某些场景下甚至能做到比duckdb还要更快
是因为他们做了大量的优化,技术拉满,推荐文章链接:https://www.mooncake.dev/blog/duckdb-parquet
官方博客:https://www.mooncake.dev/blog
五、声明 若文中存在错误或不当之处,敬请指出,以便我进行修正和完善。希望这篇文章能够帮助到各位。
文章转载请联系,谢谢合作